

Quick Summary: AI hallucinations remain a major barrier to enterprise adoption, with error rates reaching up to 40% in critical tasks. Retrieval-Augmented Generation (RAG) improves reliability by grounding outputs in verifiable data, reducing hallucinations by over 40% and boosting accuracy; here’s what the latest 60+ statistics reveal about building AI you can actually trust.
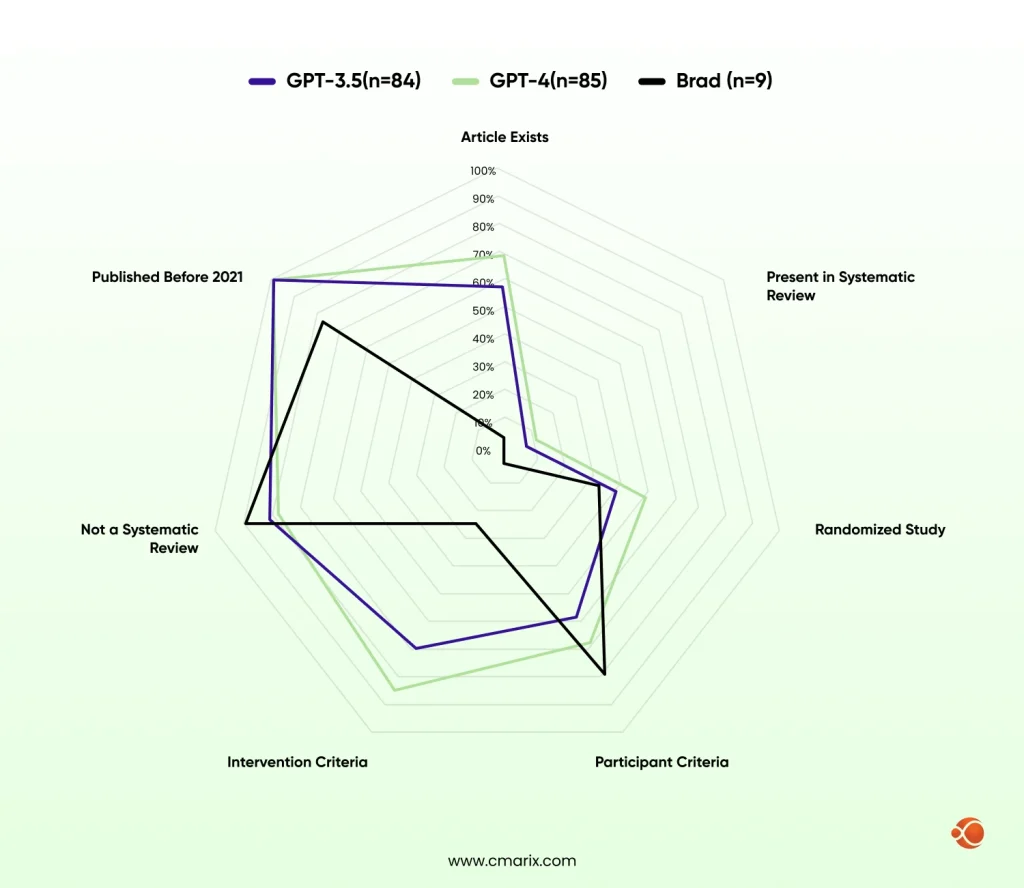
AI systems hallucinate very confidently, consistently, and at scale. MIT Sloan research confirms that LLMs generate inaccurate or fabricated content at rates that vary by model and task. A Journal of Medical Internet Research found in a peer-reviewed study the hallucination rates of 39.6% for GPT- 3.5, 28.6% for GPT-4, and 91.4% for Bard in systematic review tasks. In a customer service bot, that’s annoying. In a clinical decision support system or legal research platform, it’s dangerous.
The main issue is that enterprise AI deployments are accelerating, but the reliability infrastructure hasn’t kept pace. The hallucination problem isn’t a bug in particular models; it’s a structural limitation of how base LLMs work. They predict statistically plausible tokens. They don’t verify facts. And when they don’t know something, they often don’t say so.
Why Trust Has Become the Primary Barrier to AI ROI
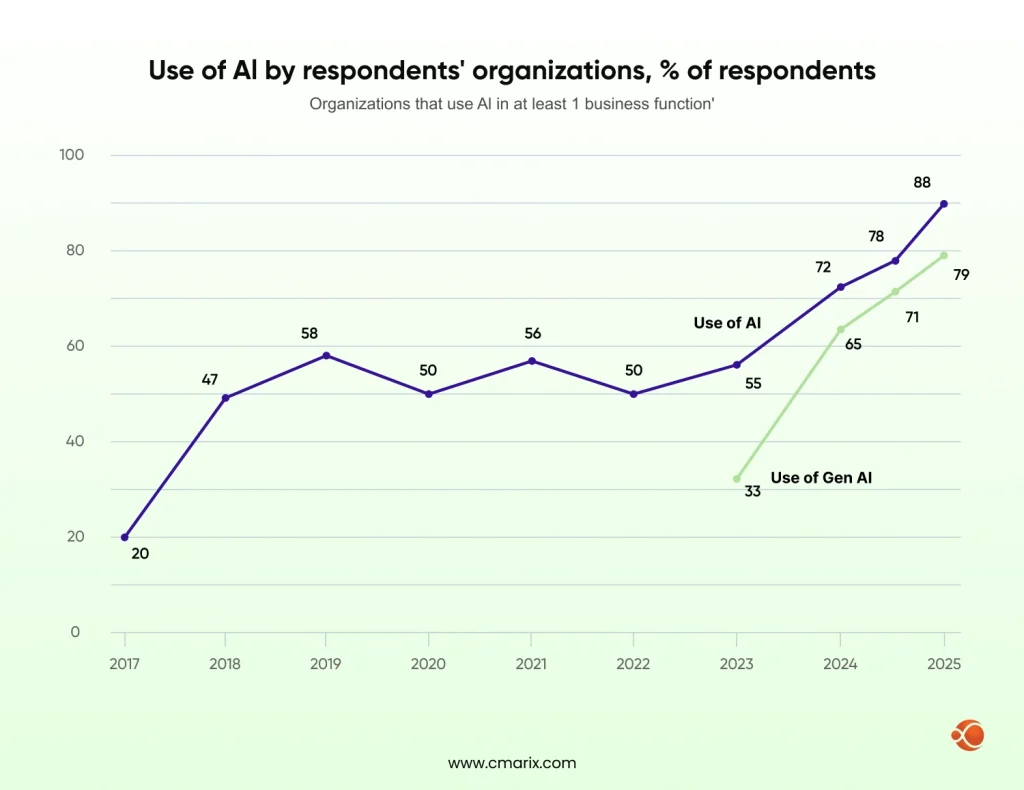
McKinsey’s state of AI research shows that while AI adoption has surged, with 78% of organizations now using artificial intelligence in at least one business function, trust and accuracy concerns are slowing or blocking deployment in high-stakes contexts. Businesses aren’t short on AI enthusiasm. They’re short on an AI they can actually depend on.
Gartner’s AI trust report found that 53% of consumers distrust AI-powered search results, and that figure climbs even higher in industries with regulatory scrutiny. When internal users don’t trust AI output, adoption rates collapse, and the ROI case evaporates. This isn’t a communication problem. It’s a technical one.
How Retrieval-Augmented Generation Directly Addresses the Reliability Gap
RAG changes the equation by tethering model outputs to verifiable, up-to-date source material. Instead of relying purely on training data, RAG systems retrieve relevant documents from a curated knowledge base before generating a response — producing outputs traceable to a source, auditable, and correctable when wrong. This is the core idea behind embedding intelligence through vector search and RAG: the model stops guessing from memory and starts reasoning over retrieved, verifiable content.
Google Research’s analysis of RAG shows that sufficient retrieved context meaningfully reduces hallucination rates. A study on PubMed evaluating RAG for clinical decision support found RAG-enhanced systems achieved an 89% performance improvement over baseline models, the difference between a system you can deploy in a regulated environment and one you can’t.
Key Takeaways — What These 60+ Statistics Tell Us
- Hallucination rates reach 39.6% for GPT-3.5 and 28.6% for GPT-4 in research tasks
- Clinical performance of RAG-based models improves up to 89%
- Legal AI hallucination rate varies between 69% and 88% for certain questions
- More than half of the consumers mistrust AI-powered search results
- While 78% of companies use AI technology, only under 31% go into production
- Context-Graph-based and hybrid RAG models beat single-retrieval models by 20-35% for accuracy tests
- By 2028, 80% of GenAI apps will be built on existing data platforms using RAG
- Infrastructure costs account for 35–50% of total RAG deployment budgets
- AI regulation to cover 50% of global economies by 2027, driving $5B in compliance investment
How to Read RAG and AI Statistics
How Researchers Define and Measure AI Hallucinations
“Hallucination” covers many different failure modes: contextual hallucination, factual hallucination, and faithfulness hallucination. Evaluation methods also vary. Stanford researchers note that assessing frameworks are themselves an active area of development, meaning vendor-reported hallucination rates may not be directly comparable across benchmarks.
Standardized AI hallucination metrics are finally maturing. Procurement teams are starting to demand them contractually, and vendors who cannot produce transparent production-rate data are losing deals. A 2025 MIT-linked research note flags a specifically troubling finding: AI models tend to use more confident language when hallucinating than when giving factual information, making it even harder to detect without systematic verification.
Why Benchmark Numbers Vary So Widely Across Vendors
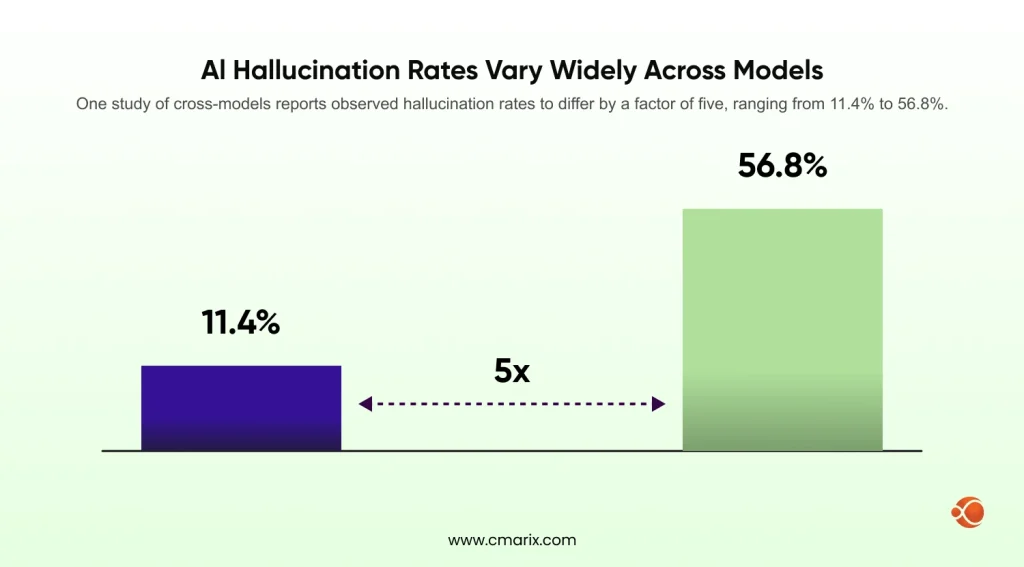
A model that claims a 3% hallucination rate based on an artificial benchmark can yield much worse error rates in real-world settings. In fact, one study of cross-models reports observed hallucination rates to differ by a factor of five, ranging from 11.4% to 56.8%.
The same study demonstrates that there is no instance of a model generating references without being prompted, indicating that hallucinations are mostly triggered by prompts. Consider the following whenever you come across such statistics: what domain did you have, and what was the retrieval setting?
How to Apply This Data to Your AI Strategy
- See which is your risk tier. Legal, healthcare, financial, and government deployments have near-zero hallucination tolerance. Internal productivity tools do not.
- Benchmark your current system using domain-specific test sets, not generic benchmarks. Measure faithfulness, factual accuracy, and source citation rate.
- Map gaps to RAG architecture decisions. Recency issues point to different solutions than specificity gaps. For teams still evaluating architecture options, expert AI PoC development scoped tightly to one high-risk use case is a faster path to real production data than running broad pilots.
- Build governance before you scale. Compliance documentation and audit trails are much easier to build in than to retrofit.
- Establish a feedback loop. Production hallucinations should feed back into the retrieval pipeline improvements, not just model fine-tuning.
RAG & AI Trust Statistics: 2026 Snapshot
The 5 Numbers That Define AI Reliability Right Now
- 39.6% – Hallucination percentage of GPT-3.5 in systematic research activities; 28.6% of GPT-4
- 53% – Consumers who have no faith in AI-powered search outputs
- 69%-88% – Hallucination rate of LLMs with regard to certain legal questions
- 89% – Enhanced performance level of RAG compared
- >40% — Hallucination reduction by MEGA-RAG multi-evidence framework vs. standalone LLMs
Hallucination Rates Across Models and Industries
| Context | Estimated Hallucination Rate |
| GPT-3.5 (systematic review tasks) | 39.6% |
| GPT-4 (systematic review tasks) | 28.6% |
| LLMs on legal queries | 69–88% |
| Legal AI tools (RAG-enabled) | ~17% |
| Medical LLMs (open-source, ungrounded) | >60% on domain tasks |
| Cross-model citation fabrication range | 11.4%–56.8% |
| ChatGPT-3.5 MS diagnosis (21 of 98 cases) | 21.4% error rate |
Your AI generates answers. But can you verify them?
Nearly half of enterprise AI users have acted on inaccurate output — RAG changes that equation.
Enterprise AI Adoption vs. Skepticism: The Trust Gap
| Metric | Figure |
| AI use cases reaching full production | 31% |
| Companies with mature AI agent governance | ~20% |
| Enterprise AI decisions based on hallucinated content | 47% |
| Consumers distrust AI-powered search | 53% |
ROI and Performance Benchmarks for RAG Systems
| Metric | Baseline LLM | With RAG |
| Hallucination reduction (multi-evidence RAG) | Baseline | >40% reduction |
| Clinical hallucinations (self-reflective RAG) | 8% | 0% (eliminated) |
| Clinical performance improvement | Baseline | +89% |
| Factual accuracy improvement (Finetune-RAG) | Baseline | +21.2% |
| GenAI model accuracy (semantics-focused) | Baseline | Up to +80% |
AI Hallucination Statistics Across Critical Industries
Healthcare: Diagnostic Errors, Patient Safety, and AI Risk
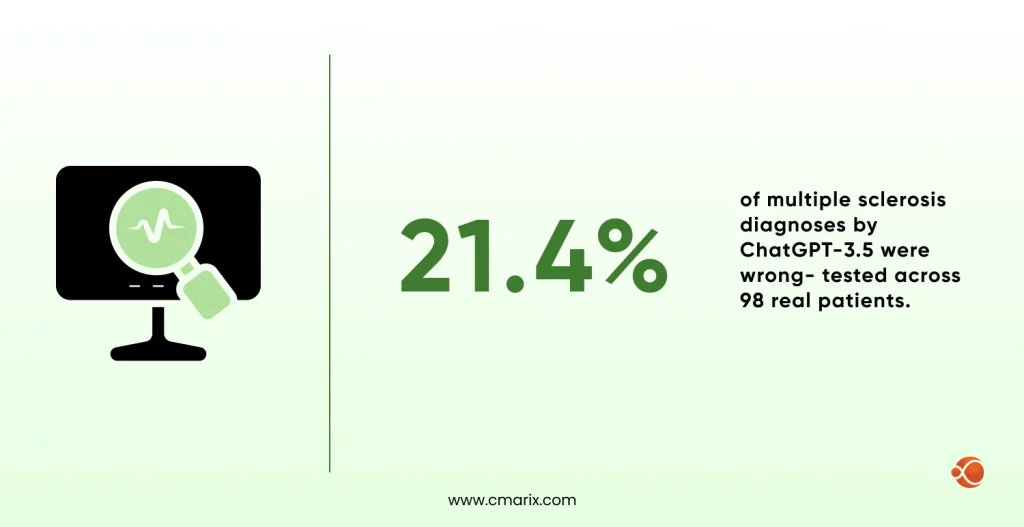
A systematic review in npj Digital Medicine analyzing 83 studies found an overall diagnostic accuracy of 52.1% for generative AI — meaning nearly half of AI-generated diagnoses were wrong. A study on NCBI evaluating the error rate in using ChatGPT-3.5 to diagnose multiple sclerosis among 98 people was 21.4%.
An article from 2025 by Frontiers in Medicine indicated that low participation of the rural population in training datasets increased false negatives in pneumonia diagnosis by 23%. A PubMed study on RAG for clinical decision support tested twelve RAG variants on 250 patient vignettes; self-reflective RAG lowered hallucinations to 5.8% — the lowest of any configuration tested.
For anyone looking to build a medical tech startup today, these hallucination rates are not an edge case to plan around. They are the central reliability problem your architecture has to solve before you touch a regulated environment.
Financial Services: When AI Miscalculates and What It Costs
AI applications in banking face a specific version of the hallucination problem: errors do not just embarrass, they trigger regulatory action. A comprehensive review on ResearchGate finds trading errors, faulty risk assessments, and compliance breaches as the three highest-cost hallucination failure modes.
| Failure Type | Risk Level |
| Fabricated regulatory references in compliance reports | Critical |
| AI-generated financial advice errors | High |
| Audit failure due to unexplainable AI output | High |
| Market decisions based on hallucinated content | 47% of enterprise AI users |
Hybrid RAG retrieval, combining dense vector search with live financial database lookups, is showing the strongest accuracy benchmarks in this sector.
Legal and Compliance: Reliability Benchmarks and Liability Exposure
Stanford HAI’s study “Hallucinating Law” tested over 200 legal queries and found:
- In response to questions on the main judgment in court cases, hallucinations occur in LLMs at least 75% of the time.
- Rates of hallucination range from 69% to 88% in responses to certain legal questions by GPTs
- Legal systems with RAG hallucinated in approximately 17% of questions, an improvement from the baseline, yet far from audit-worthy without further measures
- LLMs frequently fail to be self-aware of their mistakes and reinforce inaccurate legal preconceptions
Legal ops teams moving fastest on AI adoption treat verifiable AI outputs as a non-negotiable requirement, not a feature to bolt on later.
Manufacturing and Supply Chain: Where AI Failures Hit Operations
According to the study regarding hallucination estimation of multilingual systems, ungrounded open-domain generation tasks, such as supply chain suggestions, result in hallucination rates of 40-80%. RAG models that utilize live supplier databases and ERP data will reduce this problem significantly.
The top investment use case: AI-assisted maintenance scheduling, where models retrieve historical equipment and maintenance log data rather than depending on general engineering knowledge.
Government and Public Sector: Trust Deficits in AI Deployment
Gartner’s 2026 predictions report warns that by 2027, fragmented AI regulation will cover 50% of the world’s economies — driving $5 billion in compliance investment. AI outputs in public administration often need to be defensible in administrative appeals and legal proceedings. A RAG architecture where every output is traceable to a specific source document is inherently more defensible than a black-box LLM response.
RAG Adoption and Performance Statistics
RAG vs. Fine-Tuning: Accuracy, Cost, and Maintenance Comparison
| Dimension | Fine-Tuning | RAG (Retrieval-Augmented Generation) |
| Factual accuracy improvement | +21.2% (combined) | +21.2% base; higher with tuning |
| Hallucination reduction (clinical) | Moderate | Up to 89% performance gain |
| Source citation capability | None by default | Native |
| Knowledge update | Re-train required | Real-time or near-real-time |
| GenAI model accuracy (with semantics) | Baseline | Up to +80% |
Most LLM fine-tuning techniques improve domain reasoning but do nothing to fix the model’s tendency to fabricate facts it was never trained on. That is the structural gap RAG fills. For companies where factual accuracy is the primary concern, RAG delivers higher ROI faster and with less retraining overhead. Fine-tuning and RAG are often complementary rather than competing.
How Much Does RAG Actually Reduce Hallucination Rates?
- Multi-evidence RAG, which involves the use of FAISS, BM25, and biomedical knowledge graph models, reduced hallucinations by more than 40% and improved accuracy by 79.13%
- RAG reduced hallucinations from 8% to zero (0%) in 100 synthetic consultations
- Increased the accuracy of factual information by 21.2% over the base model
- Hallucinations reduced to 5.8% across 250 patient vignettes
What counts are not the numbers about reductions but those about the precision and recall of the retrieval engine. The effectiveness of a RAG system depends on its ability to retrieve relevant content.
Latency, Scalability, and Infrastructure Benchmarks
| System Configuration | Avg. Response Latency | Accuracy Score | Note |
| Base LLM only | ~800 ms | Variable | No citation capability |
| RAG (sparse / BM25 retrieval) | ~120ms fast path | Lower precision | Faster but less accurate |
| Hybrid RAG (dense + sparse + cross-encoder) | Higher | P@5 ≥ 0.68, nDCG@10 ≥ 0.67 | Balanced retrieval performance |
| Self-reflective RAG | Higher | 5.8% hallucination rate | Improves reliability |
| Agentic RAG (multi-step) | 3,000ms+ | Highest accuracy class | Most advanced, slower response |
Vector databases account for 20–35% of RAG infrastructure costs at scale.
Top Enterprise Use Cases Driving RAG Investment in 2026
The highest-growth RAG use cases are those where hallucination has the most visible business cost. Internal knowledge management leads; businesses using RAG to power AI assistants over their own documentation and institutional knowledge, where the knowledge base is inherently verifiable and controlled.
Gartner explicitly states that RAG is now a foundation for deploying GenAI applications, giving explainability and composability with LLMs across compliance monitoring, technical support, contract analysis, and competitive intelligence.
AI Governance, Compliance, and Trust Statistics
Enterprise AI Governance Adoption Rates by Sector
| Sector | Note |
| Financial Services | Leads AI governance adoption; regulatory compliance embedded in culture |
| Healthcare | Growing under HIPAA AI guidance (2025) |
| All sectors | Only 20% have mature AI agent governance |
| Global | AI regulation expected to cover 50% of economies by 2027 |
Most enterprises have AI policies on paper, but the research shows that only one in five has audit-ready processes for tracking individual AI agent decisions at scale.
Explainability and Audit Requirements
Explainability is no longer academic; it’s a procurement requirement in regulated industries. Gartner’s AI TRiSM framework positions organizations that don’t manage AI risks as exponentially more likely to experience project failures and compliance breaches. RAG is well-suited here: because every response references specific retrieved documents, it’s straightforward to log what was retrieved and surface it alongside the response — creating the audit trail regulators expect.
Major Regulations Shaping AI Trust Globally in 2026
- EU AI Act compliance: Audit trail in case of high-risk AI, human participation, and risk assessment with explanation
- AI Executive Order for the US: Businesses will perform AI risk assessments and take the help of humans in decision-making where AI is involved
- HIPAA AI Guidelines (2025): AI-created medical documents must comply with all regulations (HIPAA) regarding precision and patient records.
- SEC AI Reporting (2025): Risk-related AI reporting by publicly traded corporations in their financial statements.
- GDPR AI Compliance: Requirements for automatic processing that have been considered applicable to decisions made through LLMs
- Fragmented global regulation: Gartner predicts AI laws will cover 50% of global economies by 2027, driving $5B in compliance investment
How Compliance Pressure Is Accelerating RAG Investment
Every one of these regulations demands traceable, auditable, source-grounded outputs; something that base LLMs structurally cannot provide. RAG closes that gap at the architecture level. Regulatory compliance AI is no longer a category you opt into; it is what the architecture has to support from day one. Gartner confirms that when LLMs are combined with business-owned datasets using RAG, accuracy is highly enhanced, with semantics and metadata playing an important role in making sure traceability.
Internal AI Acceptance: Employee Trust Scores and Adoption Friction
47% of enterprise AI users have made at least one major business decision based on potentially inaccurate AI-generated content. The trust gap is measurably smaller in RAG-powered systems where outputs are accompanied by source citations. Users who can see why the AI gave a particular answer report significantly higher confidence scores. This isn’t just a UX improvement. It’s a structural difference in how accountable the system actually is.
What’s Holding RAG Back — Challenges and Limitations
Data Quality and Retrieval Accuracy: The Foundation Problem
The accuracy of RAG models is contingent upon the information stored in their knowledge bases. Studies conducted on multi-agent RAG models on arXiv revealed that there were retrieval errors in15-40% of the questions posed to the model despite its optimal design.
The most common failure mode isn’t the model hallucinating; it’s the retrieval system returning wrong, partial, or outdated documents. Knowledge base quality must be treated as a continuous engineering problem, not a one-time setup task.
Knowledge Base Gaps and Context Window Constraints
The arXiv Agentic RAG survey identifies coverage gaps, misinterpretation, retrieval failures, and overconfident gap-filling as the four critical failure modes in RAG systems. Context window constraints add complexity — modern models handle larger contexts than two years ago, but very long documents still need chunking, and the chunking strategy significantly affects retrieval quality.
Infrastructure Costs and Build-vs-Buy Tradeoffs
| Approach | Upfront Cost | Annual Maintenance | Time to Deploy |
| Build a custom RAG | $80K–$600K | $40K–$150K | 3–9 months |
| RAG platform (SaaS) | $20K–$80K | $30K–$110K/year | 4–12 weeks |
| Embedded RAG (via API) | $5K–$35K | Usage-based | 1–4 weeks |
| Hybrid (platform + custom) | $40K–$250K | $25K–$100K | 6–16 weeks |
The cost mentioned above is approximated.
Costs above are approximated. Whether you are evaluating generative AI development services or building in-house, these tradeoffs are not just financial. Speed to deployment and depth of control pull in opposite directions. Choosing the right enterprise RAG architecture early determines not just your accuracy ceiling but how defensible your outputs are when a regulator or auditor comes asking.
Gartner predicts 30% of GenAI pilots advancing to large-scale production will involve internal builds by 2028, suggesting more enterprises are choosing depth of control over speed of deployment.
Security and Privacy Risks in Retrieval Pipelines
AI security risks in RAG systems are distinct from model-level risks. The retrieval pipeline itself becomes an attack surface most teams are not thinking about. Here are the main threat vectors and how to counter them:
- Prompt injection via retrieved documents — Malicious content in knowledge base documents can hijack model behavior. Countermeasures: Input sanitization and output validation at the retrieval layer.
- Unauthorized data access — RAG systems without document-level access controls can expose information to unauthorized users. Countermeasures: Query-time permission checks tied to user identity.
- Leakage from embedding model data — The API embedding sensitive documents could record or cache the information. Countermeasures: In-house embedding models used for sensitive information.
- Poisoning through retrieval — Hackers who have write privileges to the knowledge repository can skew AI output intentionally. Countermeasures: Write privilege restrictions and document provenance verification.
- Cross-tenant information leakage — Vector repositories not isolated by namespace will result in cross-leaking between tenants. Countermeasures: Strict namespace enforcement and tenant-based indexing.
Secure AI software development means thinking about the retrieval pipeline as an attack surface, not just the model layer.
Future of Trustworthy AI: Trends and Predictions Through 2030
Hybrid Architectures: Combining RAG with Fine-Tuning
It’s not RAG, nor is it fine-tuning for the future enterprise AI, but both of those techniques are combined in a deliberate manner. In Finetune-RAG from arXiv, a technique of fine-tuning was used in order to overcome the issue of hallucinations when introducing information irrelevant to RAG into a pipeline.
Context-Graph Grounded RAG, which structures retrieved knowledge as a graph rather than flat chunks, consistently outperforms single-retrieval approaches by 20-35% on accuracy benchmarks. It is among the most promising directions for teams that need both precision and explainability.
Real-Time Retrieval and Dynamic Knowledge Systems
Static knowledge sources become outdated fast. Agentic RAG agents go further than standard retrieval by combining reflection, planning, tool use, and multi-agent collaboration within the pipeline. This makes them capable of pulling from live APIs and real-time databases in ways that static RAG pipelines cannot. In A-RAG (arXiv, 2026), retrieval modules based on keywords, semantics, and chunks work together to search across dynamic sources.
This makes them capable of retrieving from live APIs and real-time databases in ways that cannot be achieved by static RAG processes. In A-RAG (ArXiv, 2026), there are retrieval modules based on keywords, semantics, and chunks for searching.
Emerging AI Evaluation Frameworks and Benchmarks
Stanford’s trustworthy AI researchers are developing evaluation methods that go beyond measuring model accuracy to evaluating system reliability in terms of relevance, reliability, and situational appropriateness.
The metrics for assessing AI hallucinations are standardizing to a point where procurement officers can start demanding it as part of a contractual obligation. Vendors who can’t show ongoing production hallucination rates with transparent methodology are increasingly losing deals.
The Role of Synthetic Data in Closing the Trust Gap
Gartner predicts 60% of data and analytics leaders will face failures managing synthetic data by 2027 — signaling both growing adoption and the complexity of making sure synthetic data accurately represents real-world scenarios without introducing new biases. Evaluation and alignment research must advance alongside capability improvements and synthetic data generation.
2030 Predictions: Where AI Reliability Is Headed
- By 2030, 0% of IT work will be done without AI — 75% augmented by humans, 25% by AI alone
- By 2027, 50% of business decisions will be augmented or automated by AI agents
- By 2027, organizations prioritizing semantics will increase GenAI accuracy by up to 80% and reduce costs by up to 60%
- By 2028, 80% of GenAI business applications will be developed on existing data management platforms using RAG
- AI regulation to cover 50% of global economies by 2027, with $5B in compliance investment required
Strategic Recommendations for Enterprise Teams
- Conduct a candid audit of your current AI hallucinations.
- Prioritize applications based on the cost of hallucinations.
- Focus on building high-quality knowledge bases before focusing on retrieval architecture.
- Design for assessment as part of the product itself.
- Make sure that your RAG architecture is aligned with your compliance philosophy.
- Working with a trusted AI consulting company during the architecture phase is significantly cheaper than retrofitting governance, audit trails, or retrieval pipelines after a compliance failure

Conclusion
There comes an end to the period when we would tolerate AI systems experimentally making things up. The regulated industry will not allow “AI can make things up” to be accepted as a limitation of the system. The risk is too high, the regulation is too direct, and having an AI system that works reliably is just a big advantage.
But RAG does not offer any magical solution; it is a choice that your AI system will operate on reliable facts. It is supported by the RAG & AI statistics for the year 2026. Peer-reviewed academic sources like Stanford HAI, NCBI, arXiv, and Gartner confirm that organizations that consider reliability to be the first class of concern get way better results than those that still tolerate hallucinations.
The question isn’t whether your organization will need trustworthy AI. It’s whether you’ll build the infrastructure for it before a high-profile failure makes the decision for you.
FAQ on RAG & AI Trust Statistics
Does RAG eliminate AI hallucinations completely in 2026?
Not entirely, but it substantially decreases them. Research indicates 0% occurrence of hallucinations under controlled circumstances and more than 40% reduction using sophisticated techniques. In practical application, effectiveness still hinges upon data accuracy and data search.
How common are AI hallucinations in legal and financial industries?
Hallucinations remain frequent in high-stakes domains. Legal AI can hallucinate in up to 69–88% of complex queries, while financial systems have led 47% of users to make decisions based on incorrect outputs.
What is the impact of hallucinations on business?
Hallucinations can trigger compliance issues, poor decisions, and loss of trust. With rates reaching over 50% in some models and weak governance in most firms, the business risk is substantial.
What is “Agentic RAG” and why is it important in 2026?
Agentic RAG leverages intelligent agents to enhance information retrieval through planning, reasoning, and iteration. Agentic RAG is particularly useful in sophisticated and risky applications that require precision and depth.
How can I increase user trust in AI-generated answers?
Show clear source citations and retrieved context to users. Combine this with confidence scoring and human review for critical tasks to make outputs more transparent and verifiable.




