

Quick Summary: Enterprise RAG architecture allows AI systems to access and use internal company data in real time, solving the limitations of static models. By combining LLMs, retrieval, and embeddings, it delivers accurate, context-aware responses. When designed with proper data pipelines, evaluation, and security, RAG transforms scattered enterprise knowledge into a reliable, scalable AI assistant.
Most enterprise AI projects don’t fail because of bad models. They fail because the model doesn’t know what the company knows. Your internal documentation, past contracts, support tickets, and knowledge bases like Atlassian Confluence, all of it exists somewhere, but the AI you deployed can’t touch any of it. That’s the core problem Enterprise RAG architecture was designed to solve.
RAG (Retrieval-Augmented Generation) is the approach that lets a LLM pull in your actual company data at query time, rather than depending on general training knowledge. And when it’s built right, it transforms a generic chatbot into a genuinely useful knowledge assistant that analysts, engineers, and support teams actually want to use.
Why Enterprise AI Knowledge Assistants Fail with Internal Data
Here’s the thing most vendors won’t tell you upfront: the majority of enterprise AI deployments struggle not because of model quality, but because of data access. General-purpose LLMs are trained on public internet data. Your company’s knowledge isn’t on the internet.
When development teams try to patch this gap by cramming internal documents into the prompt, they hit context window limits fast. And when they try to fine-tune instead, they find it’s costly, slow to update, and still doesn’t handle real-time document retrieval well.
- The AI gives confident but wrong answers, because it’s hallucinating details it was never trained on.
- It can’t reflect knowledge that changed last week, because fine-tuned models are static snapshots.
- The employees stop trusting it and adopt flatlines, even when the underlying model is solid.
What companies need is a system that actively fetches relevant internal knowledge at the moment of each query, passes it to the model as context, and generates responses grounded in real documents. That’s RAG. And when it’s designed for enterprise scale, it becomes something much more powerful.
What Is Retrieval-Augmented Generation (RAG) in Enterprise AI?
RAG was originally introduced by Facebook AI research as a way to combine parametric knowledge (what the model learned during training) with non-parametric knowledge (documents retrieved at runtime). The idea is that before generating a response, the system retrieves relevant passages from a document store and feeds them into the model as additional context.
In enterprise AI, this means the model can answer questions about your particular policies, your codebase, your customer data, or your internal research, without ever being retrained. You update the document store, and the AI’s knowledge updates with it. What makes Enterprise RAG architecture different from a basic RAG setup is the scale of the problem. You’re not retrieving from a few hundred documents. You might be retrieving millions of records across multiple data sources, with different access permissions for different users, in a regulated environment where a wrong answer carries real consequences.
- Basic RAG: a vector store + a retriever + an LLM. Works for prototypes.
- Enterprise RAG: adds security layers, multi-tenancy, query routing, metadata filtering, re-ranking, observability, and production-grade infrastructure.
The gap between those two is where most enterprise projects get stuck. Building the first one takes a weekend. Building the second one takes a real architect.
Building a RAG pipeline that actually works in production is a different problem than building one that works in a demo. Want to get the architecture right from the start?
How Enterprise RAG Architecture Works: Step-by-Step Pipeline
At its core, a RAG pipeline operates in two main phases: indexing (running in the background) and retrieval + generation (executed at query time). But, in enterprise environments, this core pipeline is supported by additional layers for security, scalability, and continuous improvement.
Let’s break it down.
Indexing Phase (Offline Processing)
This phase prepares enterprise data so it can be efficiently retrieved later.
- Document Ingestion: Raw data is collected from multiple sources — PDFs, Word documents, Confluence pages, databases, and Slack exports — using connectors.
- Chunking: Documents are split into smaller segments. The chunk size directly impacts performance — too small loses context, too large reduces retrieval precision.
- Embedding: The chunks will be mapped into vectors using an embedding algorithm, which allows for semantics understanding rather than simple keyword matching.
- Metadata Tagging: Tags such as source, author, date, department, and access control level will be applied to each chunk.
- Vector Storage: These vectors are stored in a vector database (such as Pinecone, Weaviate, or pgvector) and indexed for fast similarity search.
Retrieval + Generation Phase (Query-Time Processing)
This phase handles user queries and generates responses in real time.
- User Question: The question asked by the user is in natural language.
- Embedding of Query: It is embedded into vectors using the same model used in indexing.
- Retrieval of Chunks: The system retrieves chunks from the vector database that are semantically more similar to the query.
- Re-ranking: An additional ranking algorithm is applied to the retrieved chunks to ensure that the most relevant chunks are passed.
- Response Generation: After receiving both the query and the retrieved chunks, the LLM will generate an output based on this input.
- Response with References: The final response provided contains citations to the sources.
Beyond the Core Pipeline: Enterprise Considerations
While these two stages form the backbone of RAG, production-grade systems include additional layers:
- Data Synchronization & Updates: Keeps embeddings consistent with evolving data
- Access Management: Makes sure that users access only relevant data
- Orchestration: Takes care of the workflow and retries
- Evaluation & Feedback Loop: Improves the quality of responses continually
- Caching & Monitoring: Improve performance and system monitoring
If you’re thinking about how this fits into your broader technical stack, it’s worth exploring cloud-native deployment approaches—RAG systems perform best when the surrounding infrastructure can scale with demand.
Key Components of Enterprise RAG Architecture Explained
Every layer of the RAG stack has options, and the choices you make compound quickly. Here are the components worth understanding in depth.
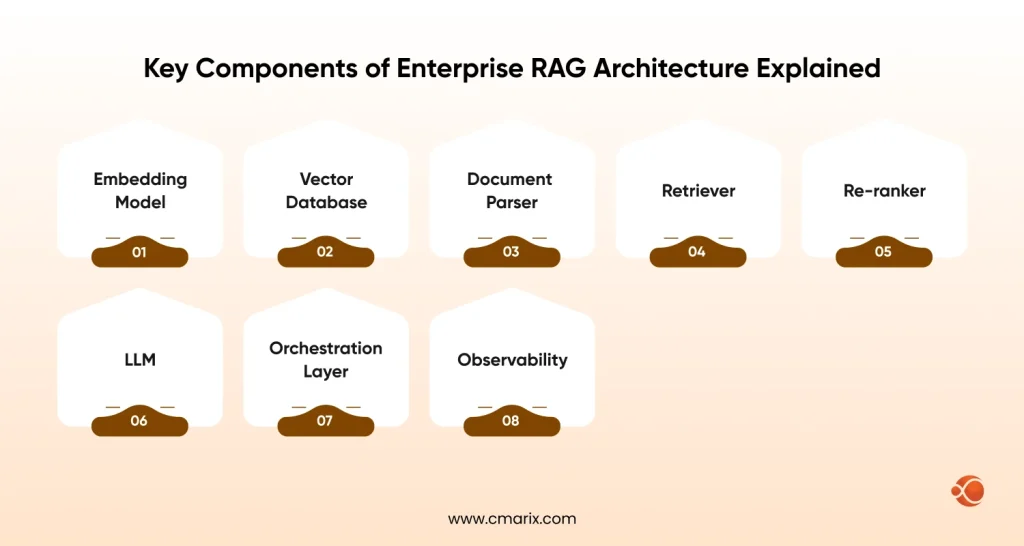
- Embedding Model: Converts text to vectors. Options involve OpenAI’s text-embedding-3, Cohere Embed, or open-source models like E5 and BGE. Your choice affects retrieval quality more than almost anything else.
- Vector Database: Stores and indexes embeddings. Key players are Pinecone, Weaviate, Qdrant, Milvus, and pgvector for Postgres-native setups.
- Document Parser: Handles extraction from PDFs, HTML, DOCX, and databases. Quality here affects every downstream step.
- Retriever: The component that takes a query vector and returns the top-k most relevant chunks.
- Re-ranker: A cross-encoder model that re-scores retrieved chunks more precisely than vector similarity alone can.
- LLM: The generation layer — GPT-4o, Claude, Mistral, or a private model, depending on your security requirements.
- Orchestration Layer: LangChain, LlamaIndex, or a custom framework that wires all the components together.
- Observability: Logging, tracing, and evaluation tools like LangSmith, Arize, or Ragas that let you understand what’s working and what’s not.
If you’re building this from the ground up, understanding the full AI product development architecture and cost breakdown will help you plan resources realistically before you commit to a stack.
Your Internal Knowledge Exists. Your AI Just Can’t Reach It Yet.
The retrieval architecture, the access controls, the evaluation pipeline; that’s where most enterprise RAG projects get stuck. Want to build it the right way from day one?
Get StartedRAG Retrieval Strategies to Improve Accuracy and Relevance
Retrieval is where most RAG systems leave performance on the table. Vector similarity search is a starting point, not an endpoint.
Hybrid Search
Combining dense vector search (semantic) with sparse keyword search (BM25 or Elasticsearch) gives you the best of both worlds. Semantic search catches conceptually related content even when the wording is different. Keyword search catches exact technical terms that embeddings sometimes miss.
Metadata-Filtered Retrieval
The retrieval through the metadata filtering approach ensures that you can narrow down the search space prior to similarity scoring. When the query is submitted by the financial analyst, it is filtered to only the documents from the finance department.
- Filter by access role to enforce permissions at the retrieval layer.
- Filter by document date to prioritize recent information.
- Filter by document type (policy vs. technical spec vs. meeting notes) based on query intent.
Cross-Encoder Re-ranking
Standard vector retrieval uses bi-encoders — the query and document are embedded separately, then compared by cosine similarity. It’s fast, but not always accurate. Cross-encoder re-ranking involves feeding the top retrieval outputs into a cross-encoder model that simultaneously evaluates both the question and document.
While more computationally intensive, this process delivers more accurate relevance scoring. Indeed, re-ranking leads to marked improvements in the quality of answers, particularly those to multi-faceted questions.
Designing the LLM Layer in RAG for Better AI Responses
The retrieval layer gets the right context. The LLM layer turns that context into a useful answer. Both have to work well.
Prompt Engineering for RAG
- System prompt structure: Tell the model clearly to answer only from the provided context. This is the primary guard against hallucination.
- Citation instructions: Ask the model to cite which document each claim comes from. This makes answers verifiable.
- Handling no-answer cases: Instruct the model to say ‘I don’t have information on that’ rather than making something up when retrieval comes back empty.
- Query rewriting: Sometimes, user questions are vague or conversational. A pre-processing step that rewrites the query into a more search-friendly form improves retrieval before the main LLM even sees it.
- Framework Selection: If you’re building custom embedding or re-ranking models in-house, evaluating PyTorch vs. TensorFlow for AI projects can save you from early refactoring later.
If you need your model to go beyond off-the-shelf behavior, you’ll want to look at LLM fine-tuning techniques as a complementary approach — though in most enterprise RAG setups, good retrieval plus a strong base model covers most use cases without fine-tuning.
GraphRAG (Knowledge Graph Augmentation)
Standard RAG retrieves individual chunks, which can miss relationships between entities. GraphRAG (Knowledge Graph Augmentation), as explored in Microsoft’s GraphRAG implementation for private data, builds a knowledge graph from your documents and uses it to traverse entity relationships during retrieval.
This is particularly useful when questions require connecting information across multiple documents — things like ‘Which projects involved both Team A and Vendor B?’ That flat chunk retrieval struggles to answer well.
Enterprise RAG Security, Compliance, and Access Control
Security in RAG isn’t an afterthought. It’s part of the architecture. A retrieval system that surfaces the wrong documents to the wrong user isn’t just a bug — it’s a compliance failure.
Vector Database Multi-Tenancy
Vector Database Multi-Tenancy means designing your vector store so that different users, teams, or clients operate in logically or physically isolated namespaces. There are a few patterns:
- Namespace isolation: Each tenant gets its own collection or namespace. Simple implementation and easy to reason about.
- Metadata-based isolation: All tenants share the same collection, but every chunk is tagged with a tenant ID, and retrieval filters enforce separation.
- Physical isolation: Separate vector databases per tenant. Maximum isolation, higher operational cost.
Amazon Bedrock provides useful guidance on how to protect sensitive data in RAG applications, including encryption at rest and in transit, VPC endpoints, and IAM-based access control for retrieval pipelines.
- Role-Based Access Control (RBAC): User roles should determine which document namespaces are searchable for them at query time.
- Data residency: For regulated industries, ensure documents and vectors stay in the right geographic regions.
- Audit logging: Every query, every retrieved document, every response — all should be loggable for compliance review.
If you’re weighing whether to run your LLM on private infrastructure or use a hosted provider, the detailed analysis of the security risks of private vs public AI models is worth reading before you decide.
How to Measure RAG Performance: Metrics That Matter
You can’t improve what you don’t measure. RAG evaluation is a bit different from standard model evaluation because you have two moving parts: retrieval quality and generation quality.
Retrieval Metrics
- Context Recall: Did the retriever surface all the chunks needed to answer the question?
- Context Precision: Of the retrieved chunks, how many were actually relevant?
- MRR (Mean Reciprocal Rank): Was the most relevant chunk near the top of the retrieval results?
Generation Metrics
- Faithfulness: Is the answer produced using the context obtained from the source, or is the AI going rogue?
- Answer Relevance: Does the response address the question posed by the user?
- Hallucination Percentage: What percent of answers contain information that wasn’t found in the retrieved sources?
Stanford’s research on RAG and AI transparency makes a strong case for evaluation frameworks that go beyond accuracy to include transparency — meaning users should be able to see and trace why the model said what it said.
Tools like Ragas, LangSmith, and Arize Phoenix have emerged specifically for RAG evaluation. Running evals against a golden question-answer dataset is the most reliable way to catch regressions before users do.
Scaling Enterprise RAG Systems for Production
A RAG system that works for 10 users with 10,000 documents needs a unique design than one serving 10,000 users with 100 million documents. Here’s what changes at scale.
- Indexing Pipeline – Async: Get rid of documents on the critical path. Utilize message queues such as SQS and Kafka to ingest documents asynchronously.
- Caching: Commonly asked questions will access the same bits repeatedly. Caching can be done either at the request level or the response level.
- Horizontal scaling: The retrieval service, the embedding service, and the LLM call are all independently scalable. Architect them as separate services.
- Vector index optimization: At large scales, approximate nearest neighbor (ANN) algorithms like HNSW or IVF-Flat in your vector store become important to keep query latency manageable.
- Load testing: Test retrieval latency under concurrent load before you launch. P99 latency matters a lot in enterprise tools that people use all day.
Common Enterprise RAG Challenges and How to Solve Them
Even well-designed RAG systems run into common friction points. Here’s what you’ll likely hit.
Agentic RAG Workflows
Simple RAG handles single-turn questions well. But what happens when a question requires multiple retrieval steps, or when answering one thing means looking something else up first? That’s where Agentic RAG Workflows come in — RAG systems that can plan a sequence of retrieval steps, call external tools, and reason across multiple sources before generating a final answer.
This is closely related to how modern enterprises are building enterprise support through autonomous AI agents — systems that don’t just answer questions but take multi-step actions on behalf of users.
| Challenge | Fix |
| Retrieval returns irrelevant chunks | Improve chunking strategy, add metadata filters, and implement re-ranking |
| The LLM ignores retrieved context and answers from memory | Strengthen the system prompt with explicit instructions to use only the provided context |
| Documents are stale | Implement event-driven re-indexing triggered by document updates, not just batch schedules |
| Latency is too high | Add caching, optimize your re-ranking step, and consider a faster embedding model for low-latency use cases |
| Users don’t trust the answers | Always surface source citations and allow users to verify by clicking through |

Real-World Enterprise RAG Use Cases and Applications
Enterprise RAG Architecture isn’t theoretical. Companies across industries are already running it in production.
- Document review in legal proceedings: Legal firms employ RAG to search relevant contracts, legal precedents, and regulations. A legal expert would ask “What is our indemnification responsibility under the Acme contract?” and receive an answer with references in seconds.
- Engineering knowledge management: Software development departments leverage RAG capabilities to create searchable documentation, runbooks, and architectural decision logs, speeding up onboarding of new developers through natural language querying the system about the history of the codebase.
- Customer support operations: Customer support representatives use RAG assistants to search across product documentation, archived case resolutions, and company policies to improve speed and consistency.
- Financial analysis: Financial analysts search company financial models, earnings call transcripts, and industry reports using the RAG interface instead of looking into folders manually.
- HR and policies Q&A: Company employees get answers to benefits and compliance questions without engaging with HR every time they need a simple answer.
If you’re thinking about how all this fits into your broader enterprise technology stack, the guide on enterprise application integration strategies covers how RAG connects with existing systems like CRM, ERP, and ITSM platforms.
RAG vs Fine-Tuning in Enterprise AI: Which One to Choose?
This comes up in every enterprise AI conversation. The short answer: they’re not competing approaches — they solve different problems.
| Approach | When to Use |
| RAG (Retrieval-Augmented Generation) | When knowledge is constantly evolving, when source citation is required, when document-level access control is needed, or when retraining cost and time are too high |
| Fine-tuning | When the model needs to adapt to specific tone, style, or domain jargon, and when fast inference at scale is required without relying on retrieval |
| Hybrid (RAG + Fine-tuning) | When you want both domain-specific tone and accurate, up-to-date knowledge, fine-tune for language style and use RAG for real-time information retrieval |
There’s a more detailed breakdown of this decision in choosing the right AI architecture for enterprise applications; it walks through specific decision criteria based on your data update frequency, latency requirements, and compliance constraints.
How to Implement Enterprise RAG: Build vs Partner Approach
Once you’ve decided to move forward with Enterprise RAG Architecture, the next question is: do you build it yourself or work with a partner?

Building In-House
- Full control over architecture decisions and data handling.
- Requires a team that knows vector databases, embedding models, prompt engineering, and production MLOps.
- Longer time to first working system; typically 3-6 months for a production-ready setup.
- Ongoing maintenance burden on internal teams.
Working with a Partner
- Faster time to value — an experienced team has already solved the problems you’ll encounter.
- Access to teams with experience in building scalable custom software frameworks and enterprise generative AI solutions — these aren’t skills that appear overnight.
- Works well for companies that want to focus internal engineers on product differentiation, not infrastructure.
- This is where AI software development earns its value; they’ve debugged the retrieval pipelines, the embedding mismatches, and the latency issues you’d spend months discovering on your own.
Whether you build or partner, you’ll need dedicated AI developers who understand both the ML side and the systems engineering side. The retrieval architecture and the production infrastructure are equally important — neglecting either one creates problems that are hard to fix later.
One increasingly common pattern: teams build a privacy-first mobile AI apps interface on top of an enterprise RAG backend, letting field employees query internal knowledge from their phones without any data leaving the secure environment.
Why Choose CMARIX for Enterprise RAG Architecture Development
Building an Enterprise RAG system isn’t just an AI problem; it’s an architecture problem. At CMARIX, we design and develop end-to-end RAG pipelines that connect your internal knowledge to production-ready AI assistants, with the security, scalability, and retrieval precision enterprise environments actually demand. From vector database design to agentic workflow implementation, we’ve built these systems before, and we know exactly where most teams get it wrong.
Conclusion: Turning Enterprise Data into an AI Advantage
Enterprise RAG Architecture is what closes the gap between a generic AI model and an AI that actually knows your business. The technology stack — vector databases, semantic chunking, cross-encoder re-ranking, metadata filtering, knowledge graphs — exists and is production-ready. The hard part is the architecture and the implementation discipline.
The companies getting the most value from RAG right now aren’t the ones with the biggest AI budgets. They’re the ones that invested time in cleaning up their data, thinking carefully about retrieval design, and building proper evaluation pipelines to measure what’s working.
If your internal knowledge is sitting in document stores that no one can search effectively, it’s a liability. Enterprise RAG Architecture is how you turn it into an asset — one that gets smarter as your organization grows and your document base expands.
The technology is ready. The question is whether your architecture is.
FAQ: Enterprise RAG Architecture
Why is RAG more effective than fine-tuning for enterprise knowledge?
Fine-tuning locks knowledge into the model during training; the moment your data changes, it’s already out of date. RAG pulls from your live document store at query time, so the AI always reflects what you actually know right now.
How does an Enterprise RAG system maintain data security?
Every retrieval request gets filtered by the user’s access role, so the system only surfaces documents that the person is permitted to see. Vectors and document chunks are stored in isolated namespaces, and all queries are logged for compliance auditing.
What is the role of an Embedding Model in RAG?
The embedding model converts both your documents and the user’s query into numerical vectors that capture meaning, not just keywords. That’s what allows the retrieval system to find conceptually relevant content even when the exact wording doesn’t match.
Can RAG assistants handle real-time data updates?
Yes — unlike fine-tuned models, you don’t need to retrain anything. You update the document store, re-index the changed files, and the assistant starts reflecting new information on the very next query.
What are the primary causes of hallucinations in RAG?
Hallucinations in RAG usually happen when retrieval fails — the system surfaces irrelevant chunks, or nothing useful at all, and the LLM fills the gap with plausible-sounding guesses. The fix is better retrieval quality, stricter prompting, and explicit instructions to say “I don’t know” when context is insufficient.
How does GraphRAG improve enterprise AI assistants?
Standard RAG retrieves isolated chunks, which means it misses connections between related entities spread across multiple documents. GraphRAG builds a knowledge graph from your data, letting the assistant traverse relationships and answer questions that require reasoning across several sources at once.




