Quick Summary: Fine-tuning vs prompt engineering is an important choice for developers building with large language models. At CMARIX, we are breaking down both approaches, showing when to rely on smart prompt design and when to apply fine-tuning for domain-specific accuracy. This guide also explores hybrid strategies that boost performance, reduce operational costs, and deliver consistent results for AI-powered applications.
Large language modules have changed AI application development. They enable strong language understanding, generation, and reasoning. To use them well, a key choice is needed between prompt engineering and fine-tuning. Understanding this difference is important for building LLM-powered applications that deliver real value.
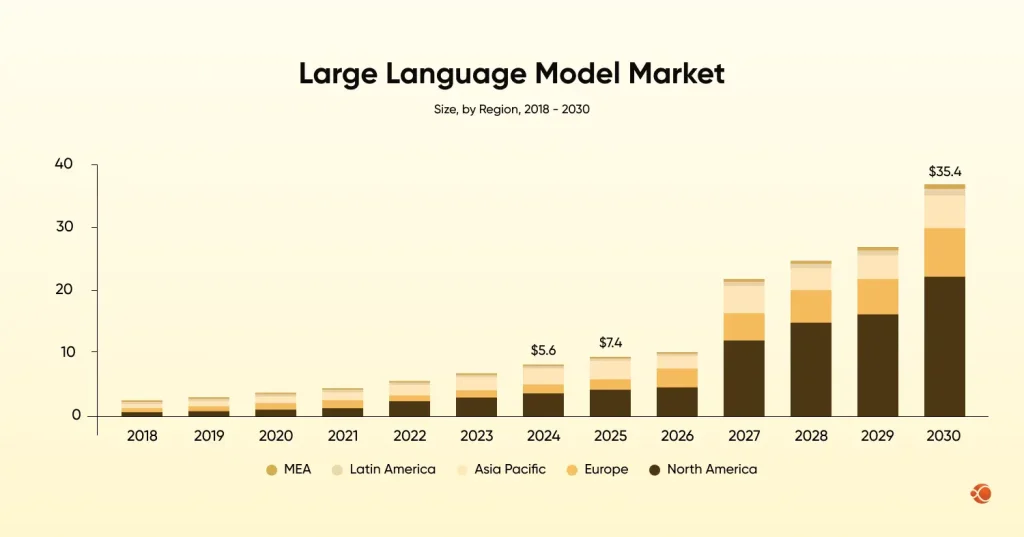
The global large language model market size was estimated at USD 5617.4 million in 2024 and is projected to reach USD 35,434.4 million by 2030.
This guide breaks down both methods, shows you when to use each, and explains how to combine them for maximum performance. You’ll learn practical model-adaptation strategies and more that work for both solo developers and enterprise teams.
What is a Fine-Tuning Model?
Fine-tuning modifies the model’s internal parameters using custom training data. You train the model on your domain-specific examples so that it learns a particular writing style, technical domain, reasoning pattern, or decision-making structure.
What are the Key Characteristics of Fine-Tuning Models:
- Learn from custom data: Trains on your examples to match tone, style, and domain.
- Task-specific accuracy: Performs much better on focused or specialized tasks.
- Consistent results: Produces more stable, predictable output every time.
- Shorter prompts needed: Understands expectations without long instructions.
- Controlled behavior: Can follow strict formats, writing rules, or brand style.
- Reliable performance: Stable and dependable in real-world use once fine-tuned.
How Fine-Tuning Works?
- Collect good examples: First, create a clean, high-quality set of examples. These examples show the model exactly how the answers should look in terms of style, tone, and knowledge.
- Train the model: The model is then trained on this dataset. During training, it learns patterns from examples and adjusts to produce similar responses.
- Test the results: After training, the model is evaluated to ensure it provides accurate, consistent answers and handles different types of questions correctly.
- Improve and repeat: If needed, more examples are added, mistakes are removed, and the model is trained again until the results are good enough.
- Use and monitor: Once ready, the fine-tuned model is deployed. Its performance is regularly monitored to ensure it stays accurate and works well over time.
We help you fine-tune AI models with domain-specific data, optimized performance, and scalable deployment to power real-world applications.
Contact UsWhat are the Top 10 Popular AI Model Fine-Tuning Techniques
| AI Model Fine-Tuning Techniques | Description |
| Full Fine-Tuning | Retrains all model parameters for maximum accuracy and deep domain adaptation. |
| LoRA (Low-Rank Adaptation) | Adds small trainable matrices so only a tiny portion of the model is updated. |
| QLoRA | A memory-efficient version of LoRA that fine-tunes compressed models with minimal hardware. |
| Prompt Tuning | Trains soft prompt vectors instead of changing model weights for lightweight customization. |
| Prefix Tuning | Adds trainable prefix vectors to each transformer layer for task-specific behavior. |
| Adapter Tuning | Inserts small adapter layers into the model and trains only those layers. |
| PEFT (Parameter-Efficient Fine-Tuning) | A family of techniques like LoRA, Prefix, and Adapters that reduce training cost by updating fewer parameters. |
| Instruction Tuning | Fine-tunes models on curated instruction–response pairs so they follow instructions more reliably. |
| SFT (Supervised Fine-Tuning) | Uses labeled examples to teach the model task-specific behavior. |
| RLHF | Optimizes a model using human feedback and reward signals to improve alignment and output quality. |
What is Prompt Engineering?
Prompt engineering is the process of crafting effective instructions to guide a pre-trained model without changing the model itself. Think of it as learning to communicate better with an expert who already knows a lot.
What are the Key Characteristics of Prompt Engineering
- Non-invasive: No model modification, only input changes.
- Fast iteration: Adjust prompts in minutes.
- Low cost: No GPU training or dataset creation needed.
- General-purpose: Works with any model that supports text prompting.
- Flexible: Suitable where requirements change often.
How Does Prompt Engineering Work
1. Defining clear instructions: Clear instructions help the model get a grasp of the task without vagueness.
2. Adding contextual information: The model performs better when equipped with background details, examples, constraints, or additional knowledge.
3. Using structured formats:
| Prompting Technique | Description |
| Chain-of-thought prompting | Encourages the model to reason step by step. Instead of giving a final answer immediately, the model explains its thinking process, which improves accuracy on tasks involving logic, math, analysis, or multi-step reasoning. |
| Few-shot prompting | Provides a few example inputs and outputs inside the prompt. The model uses these examples as patterns and generates similar responses. This method is effective when you want the model to follow a specific style, tone, or structure without training. |
| Role-based prompting | Assigns the model a specific role such as “Act as a data analyst” or “Act as a senior developer.” This narrows the model’s perspective and makes its responses more focused, relevant, and aligned with the assigned persona. |
| Step-by-step instructions | Breaks a task into smaller actions that the model must follow in order. This reduces ambiguity and ensures consistent results for tasks requiring clear procedures or structured formatting. |
| Conditional prompting | Uses “if–then” style conditions or rules inside the prompt. The model generates responses based on specific criteria, which provides more control over the tone, format, or logic of the output. |
4. Iterative refinement: The prompt is tested, updated, and retested until the output matches expectations.
5. Using prompt patterns: Design patterns such as “Act as…”, “Follow these rules…”, “Given the examples above…” help shape model behavior.
LLM fine-tuning takes a different approach; it focuses on foundation model customization on specific data to change how the LLM behaves. This is ideal for situations and use cases where you want to personalize a generic LLM into a tailored LLM model, leveraging various model adaptation strategies and techniques.
How to Improve LLM Accuracy Prompts
Prompt engineering best practices include:
- Be explicit: Give clear instructions, context, and examples.
- Use structure: JSON, XML, or markdown to help organize complex requests.
- Add examples: Include 2-5 examples of what you want.
- Test systematically: Try variations and measure what works.
- Chain prompts: Break complex tasks into steps.
Here’s prompt engineering for developers in action:
Weak Prompt: Analyze this code
Better Prompt: You’re a senior code reviewer. Analyze this Python function for:
1) bugs, 2) performance issues, 3) security problems, and 4) style improvements.
Give specific line numbers and actionable fixes for each issue.
How to Train an LLM on Domain-Specific Data

Domain-specific LLM training takes several forms, and each has different trade-offs for organizations working with AI software development services.
Full Fine-Tuning:
The AI model fine-tuning development process updates all model parameters for maximum customization; this method offers complete control over model behaviour but requires substantial computational resources. This is also the usual method used by organizations with dedicated AI infrastructure, which typically builds highly specialized models that require deep domain knowledge.
Transfer Learning in NLP:
Transfer learning provides a balance between customization and efficiency in NLP. It reuses the prior knowledge across new domains. This has become a standard procedure for specialized models. The model retains the general language understanding it has acquired while learning domain-specific patterns in your training data.
Parameter-efficient Fine-Tuning:
LoRA-based fine-tuning, or Low-Rank Adaptation, adjusts only a small subset of parameters, which significantly reduces computational overhead. This is the route many companies take when they want lighter AI solutions: fine-tuning achieves 90% of full fine-tuning performance while requiring only 1% of the computational cost. This opens up the possibility of custom LLM development even for teams without large GPU clusters.
We create intelligent apps with robust AI integration, transparent costs, and scalable architecture to drive innovation for your business.
Contact UsWhen To Fine-Tune an LLM Instead of Using Prompts?
Fine-tuning large language models becomes necessary in specific scenarios where prompts alone can’t deliver the performance you need.
What are the clear signs your project needs fine-tuning?
| Criteria | Why It Matters |
| Domain-specific terminology | Fine-tuning helps the model accurately understand and generate medical, legal, financial, or other technical jargon that general-purpose models often misinterpret. |
| General format requirements | Tasks that demand strict formats, such as structured reports, compliance documents, or templated outputs, benefit from a model trained to follow those patterns consistently. |
| Performance at scale | Smaller fine-tuned models can outperform large general models in latency-sensitive environments, especially when high throughput is required. |
| Privacy requirements | In cases involving confidential or regulated data, fine-tuning a model for an on-premise or private cloud environment ensures compliance without exposing information. |
| Behavioral alignment | Fine-tuning embeds consistent tone, style, personality, or rule-based behavior directly into the model, eliminating the need for long prompts. |
| Cost optimization | When processing millions of queries, fine-tuned compact models significantly lower inference costs compared to repeatedly prompting larger models. |
Organizations investing in AI model fine-tuning development see the best returns when building production systems that process millions of requests with consistent quality requirements.
Fine-Tuning vs. Prompt Engineering: What’s the Real Difference?
While both fine-tuning and prompt engineering improve LLM performance, they do so in fundamentally different ways. Developers often confuse them, but understanding their distinctions is critical for building reliable, scalable AI systems.
- Prompt engineering shapes the input.
- Fine-tuning reshapes the model.
Prompt engineering optimizes how you communicate with the model. Fine-tuning optimizes how the model internally behaves across tasks.
Here are the key decision metrics that you should keep in mind before committing to one between fine-tuning vs prompt engineering:
Differences between Prompt Engineering vs Fine-Tuning: Quick Comparison Table
| Factor | Prompt Engineering | Fine-Tuning |
| Control | Adjusts outputs through instructions; good for quick behavior tweaks. | Hard-coded behavior; ideal for stable rules, formats, and domain logic. |
| Consistency | Can vary with wording or context. | Highly consistent and predictable across all inputs. |
| Scalability | Longer prompts increase cost and latency. | Short prompts after training reduce cost; great for high-volume apps. |
| Data Needs | No dataset needed. | Requires curated training data. |
| Domain Knowledge | Added temporarily through prompts. | Permanently embedded in the model. |
| Long-Term Cost | Cheaper upfront; expensive at scale. | Costly to start; cheaper over time with large workloads. |
1. Depth of Control
If you only need to adjust outputs for specific scenarios, prompt engineering works really well. It allows you to guide tone, style, reasoning steps, and output structure. All this without changing how the model actually works. The model simply follows your instructions without internalizing them.
Fine-tuning gives the model true behavioral control. By training it on high-quality examples, you embed domain knowledge, style preferences, and workflow rules. Once trained, the model remembers these patterns and applies them automatically, even with minimal prompting.
Think about it: If your project involves generating legal contracts, financial reports, or branded content at scale, would you prefer the model to figure it out every time from a prompt, or to internalize the rules and kickstart an automated, self-reliant system that provides the outputs automatically?
2. Consistency of Output
The thing about prompt engineering is that even the smallest changes in wording or context can yield totally different outputs. Having a framework or set of guidelines helps eliminate such deviations as much as possible, but it doesn’t guarantee consistency.
A fine-tuned model internalizes patterns and domain knowledge. It is then able to produce stable and predictable outputs across diverse inputs.
Ask yourself: Does your application require high accuracy every single time? Enterprise AI integration for customer support, compliance documentation, and structured reporting all need consistency. Fine-tuning helps avoid costly errors in these scenarios.
3. Scalability and Performance at High Volume
Prompt engineering is excellent for small-scale testing, rapid iteration, or dynamic tasks. But long or complex prompts increase token usage, slow down inference, and can get expensive when scaled.
Once a model is fine-tuned, behavior is embedded, and prompts can be minimal. This reduces inference cost and latency, making fine-tuned models ideal for high-volume production applications.
If your company expects millions of interactions per month, consider automated code reviews, chatbots, or large-scale data analysis. Would you rather rely on long prompts every single time, or would you prefer a model that already knows the rules? Fine-tuning clearly becomes the better choice.
4. Data Requirements
Prompt engineering requires no dataset. You only need clear instructions and, optionally, a few examples in the prompt. This makes it perfect for prototypes, experiments, or testing new features quickly.
Fine-tuning requires high-quality, curated datasets. The more representative your examples, the more accurate and reliable the model becomes. Poor-quality data can lead to unpredictable or incorrect behavior.
Know what you want: Do you want a fast, low-effort solution for testing new features, or a reliable system that performs consistently with domain knowledge? Prompt engineering works well for the former; fine-tuning pays off for the latter.
5. Adaptability to Complex or Domain-Specific Knowledge
You can temporarily inject context into a prompt, but the model won’t retain that knowledge beyond that interaction.
Fine-tuning embeds domain knowledge directly into the model. Terminology, rules, and reasoning patterns are internalized, making the model more accurate and fluent for specialized fields such as healthcare, legal, finance, or technical domains.
Ask yourself: Does your project require repeated access to specialized knowledge? Medical diagnosis tools, legal contract analysis, or financial forecasting systems all benefit from a fine-tuned model that understands the domain without needing long prompts every time.
6. Cost Efficiency Over Time
Prompt engineering is cheaper upfront because no training is needed. However, frequent or large-scale usage can become expensive due to long prompts and repeated model calls.
Fine-tuning comes with higher initial costs but reduces operational expenses over time. Fine-tuned models are faster, more efficient, and often outperform larger general-purpose models in latency-sensitive or high-volume environments.
Think about it: if your system handles millions of queries, such as AI-powered customer support, automated content generation, or document processing. Would you rather pay repeatedly for long prompts or invest in a fine-tuned model that speeds up processing and lowers costs? For long-term efficiency, fine-tuning is usually the smarter choice.

Should I Use Prompt Engineering or Fine-Tune My Model?
The choice between LLM fine-tuning vs prompt engineering depends on several factors. Here is a basic decision framework that can help make the entire process a lot easier:
Use Prompt Engineering for situations when:
- You need quick results and rapid iteration.
- Requirements change frequently.
- Your team doesn’t have enough training data (sample size less than 500 examples).
- You are on a limited budget.
- Your team is focusing on building a prototype or MVP for now.
- The task is general-purpose.
- You feel like experimenting with zero-shot prompting capabilities.
Use Fine-Tuning When:
- You have 1,000+ high-quality training examples.
- Consistency is critical for your project’s success.
- You need specific domain expertise embedded.
- Latency matters (smaller models respond faster).
- You’re building for production scale.
- You have the bandwidth to build and train AI models.
- Privacy requires on-premise deployment.
- Long-term cost efficiency is a priority.
For developers working with AI consulting services, starting with prompt engineering helps validate the use case before investing in fine-tuning infrastructure.
Can You Combine Prompt Engineering and Fine-Tuning?
You know, unlike many definitive choices in life, choosing between prompt engineering and fine-tuning doesn’t need to be one. One of the best LLM optimization techniques mixes both methods. Instead of seeing this as LLM fine-tuning vs. prompt engineering, see it as two complementary strategies towards building a robust LLM-powered application.
Here is a simple LLM optimization process we follow at CMARIX:
CMARIX’s 4 Phase Approach to LLM Performance Optimization
Phase 1: Discovery and Baseline through Prompt Engineering
Every project starts by exploring the capability of well-crafted prompts. We experiment with zero-shot, few-shot, and structured instruction formats to see how far the base model can go.
This is generally a 1-2 week phase that requires very little investment. You begin to see early improvements as we gather real performance data.
Phase 2: Performance Analysis and Gap Identification
Once the baseline is established, we assess where the model is succeeding and where it’s struggling. We document issues such as inconsistent outputs, reasoning gaps, format errors, latency spikes, or escalating costs.
We also map these observations to business-level metrics such as accuracy, cost per request, user satisfaction, and speed.
Phase 3: ROI-Driven Fine-Tuning Strategy
Before recommending any fine-tuning path, our team performs a full Return on Investment analysis. This includes:
- Data Collection and Cleaning Requirements
- GPU or TPU training costs
- Ongoing monitoring and maintenance
- Deployment considerations
- Expected performance improvements compared to the current baseline
Based on this, we present different options for fine-tuning, including LoRA-based lightweight tuning and full-scale model customization. Depending on your budget, timeline, and long-term roadmap, you can pick the option that works for you.
Phase 4: Hybrid Implementation
Most real-world use cases benefit from a blended approach. CMARIX develops hybrid systems that fine-tune models on stable, high-value tasks and apply prompt engineering to edge cases and evolving requirements. This approach will keep the system flexible, efficient, and future-proof.
Our results so far: Most clients see an improvement in output quality of 40 to 60 percent while reducing long-term operational costs by 30 to 50 percent.
Future Trends: Where LLM Optimization Is Heading
1. Smaller, Specialized Models Replacing Massive General Models
- Companies are shifting from huge, general-purpose LLMs toward smaller models fine-tuned for specific workflows.
- Compact models offer faster inference, lower costs, and easier on-device deployment.
- Domain-specific LLMs (healthcare, finance, legal, supply chain, customer support) are becoming the norm.
- Teams will increasingly maintain multiple lightweight AI solutions rather than a single large model for everything.
2. Growth of Automated Prompt Optimization Tools
- Tools that automatically generate, test, and refine prompts are becoming standard.
- AI-driven prompt evaluators can measure clarity, relevance, hallucination risk, and adherence to tone.
- Optimization cycles that once took days can now be completed in minutes using AI-powered loop testing.
- This reduces manual experimentation and lets teams scale prompt engineering efficiently.
3. Low-Cost Fine-Tuning Through LoRA and Other Lightweight Methods
- LoRA, QLoRA, and other parameter-efficient techniques make fine-tuning dramatically cheaper.
- Businesses can fine-tune large models using consumer-grade GPUs instead of expensive infrastructure.
- These approaches shorten training cycles and reduce operational overhead.
- Teams are able to quickly update models as data evolves without retraining from scratch.
4. Real-Time Personalization Using Retrieval + Fine-Tuning
- Today, it is becoming clear that the new state of the art is hybrid systems that combine RAG with small, fine-tuned modules.
- Real-time personalization enables models to adapt immediately to user profiles, preferences, or tasks.
- This approach reduces hallucinations by grounding responses in live data.
5. On-Device and Edge LLM Deployment
- Devices like smartphones, IoT systems, and enterprise machines are now powerful enough to run compact, optimized language models.
- Running models directly on the device improves privacy because data stays completely local.
- It also reduces latency issues since requests do not need to travel to a cloud server.
- This shift is making the way for offline AI assistants, smarter industrial automation, and secure, private AI copilots that operate in real time.
6. AI Models That Self-Improve Through Feedback Loops
- Modern LLMs can continually improve through feedback-driven learning systems.
- Reinforcement learning, human feedback (RLHF), and automated reward models help models understand what “good” behavior looks like.
- Synthetic data generation accelerates improvement even further by generating high-quality training inputs without manual effort.
- These LLM models will rely less on static training datasets and more on real usage patterns, making them smarter with every interaction.
Wrapping Up!
Instead of debating over LLM fine-tuning vs. prompt engineering, it is important to understand their fundamentals, why they exist, what purpose they serve, and how both can be implemented at different parts of the same system to get the best LLM optimization strategy for all your projects moving forward.
FAQs for Fine-Tuning vs LLM Comparison
Is fine-tuning always better than prompt engineering for performance?
Fine-tuning isn’t always better; it’s only superior when the model must learn domain-specific patterns that the base model doesn’t naturally capture. Prompt engineering is faster, cheaper, and often performs just as well for general reasoning or structured tasks.
How do I decide if my use case requires fine-tuning or a more advanced prompting technique?
If the task relies on consistent formatting, workflow logic, or specialized terminology, fine-tuning adds measurable reliability. If the task varies or evolves frequently or demands flexible reasoning, advanced prompting techniques are usually sufficient.
Which approach is more cost-effective for a high-volume, production-level application?
Prompt engineering has a lower upfront cost but may require longer prompts, increasing inference cost at scale. Fine-tuning reduces per-call token usage and improves consistency, making it more cost-efficient for high-volume production workloads.
What are the minimum data requirements to effectively fine-tune a model?
Light fine-tunes can work with 50–500 high-quality examples, while domain-heavy or style-specific tasks typically need 1,000+ samples. The quality, clarity, and consistency of data usually matter more than the raw quantity.
What development expertise is required for each technique: prompt engineering vs. fine-tuning?
Prompt engineering requires strong reasoning skills, domain clarity, and an understanding of model behavior. Fine-tuning requires dataset curation, evaluation pipelines, and familiarity with training parameters, versioning, and experimentation control.
How does the choice between fine-tuning and prompt engineering affect my model’s ability to adapt to new information?
Prompted models adapt quickly because the logic lives in the prompt rather than the model weights. Fine-tuned models are more stable and specialized but require retraining or additional data updates whenever new information needs to be encoded.