Quick Summary: Enterprises are moving fast on AI, but sending sensitive data to third-party APIs isn’t always an option. This guide breaks down how to deploy private LLMs on AWS, Azure, and on-prem infrastructure, covering architecture options, security and compliance requirements, real cost tradeoffs, and a practical decision framework to help you pick the right deployment model for your specific situation.
Something shifted in enterprise AI adoption over the last couple of years. It stopped being a question of whether to use large language models and became a question of where to run them and who controls the data.
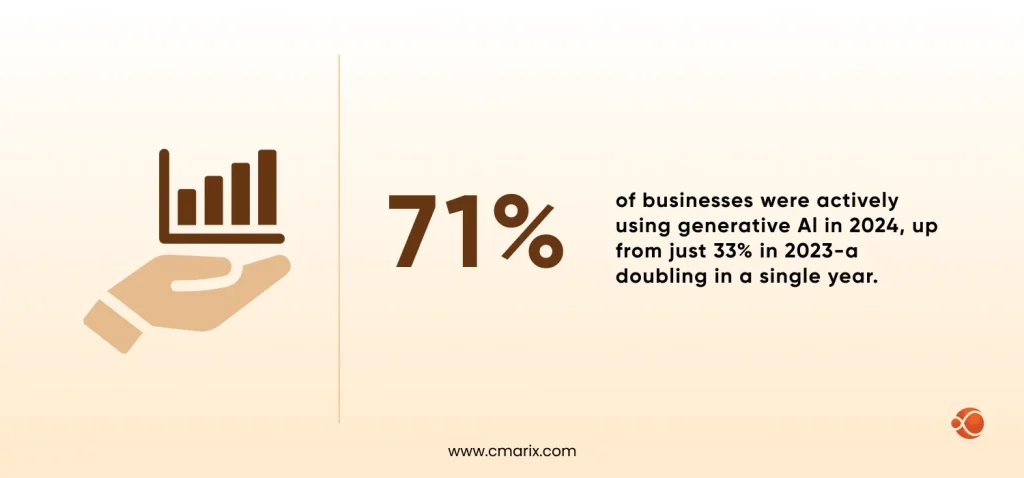
The numbers back this up. 71% of businesses were actively using generative AI in 2024, up from just 33% in 2023, a doubling in a single year. But right alongside that growth came a harder conversation: what happens to your data when you send it to a third-party API? Who sees your prompts? Can you prove to a regulator that your AI system meets their standards? That’s exactly why private LLM deployment has become the architecture of choice for enterprises that can’t afford to wing it on data control.
This post breaks down how enterprises are actually building these systems; what the tradeoffs look like, and how to figure out which model fits your situation.
What Are Private LLMs? A Clear Enterprise-Focused Explanation
A private LLM is a large language model that runs entirely within an environment your organization controls. No shared infrastructure, no third-party model providers processing your inputs, no ambiguity about data handling.
This is different from calling OpenAI’s API or using a SaaS AI tool. In those cases, your data leaves your environment. With a private deployment, the model lives inside your VPC, your data center, or a cloud account you own, and your data never crosses a trust boundary you haven’t explicitly defined.
The model itself might be open-source (e.g., Llama, Mistral, Falcon) or a licensed enterprise model (such as those available through AWS Bedrock or Azure OpenAI with private endpoints). What makes it “private” isn’t the model; it’s the infrastructure and access controls around it.
Why Enterprises Are Choosing Private LLM Deployments
Data Privacy and Security in Private LLM Infrastructure
The most immediate driver is simple: enterprises have data they can’t share. Patient records, financial transactions, legal documents, and M&A discussions this is information where even a low-probability data exposure has catastrophic consequences.
Private deployments address this through:
- VPC Service Controls on AWS or Azure’s private endpoint architecture, ensuring inference traffic never leaves your controlled network perimeter
- Air-gapped LLM orchestration for the most sensitive use cases, completely isolating the model from external networks
- Inference endpoint security treating the prompt-accepting API as the attack surface it actually is
If you’re evaluating AI security risks and mitigations for your firm, the NIST AI risk management framework is the most practical starting point for structuring that conversation.
Regulatory Compliance and Enterprise AI Governance
Compliance demands are also changing the way in which deployment decisions are made, just as technology preferences are:
- HIPAA requires stringent access control and audit trails
- GDPR requires data to be kept within the boundaries of the EU
- The EU AI Act is creating new demands related to high-risk AI systems
- Australia’s guidance on Generative AI and the UAE’s national AI policy are establishing data residency expectations that make shared-cloud AI deployments increasingly complicated
Running your LLM privately gives your compliance team something concrete to point to: the model runs here, access is logged here, data never leaves this perimeter.
Cost Optimization Strategies for Large-Scale LLM Deployment
Small-scale API pricing is hard to beat. At scale, the opposite is true. When you’re making millions of inference calls per day, the cost per token of using a managed API is a key line item. With private deployment, you’re able to:
- Avoid paying for capacity you don’t use
- Right-size compute for your actual usage patterns
- Optimize batch processing windows to reduce peak load costs
Compute-as-a-Service (CaaS) for AI that is offered through both AWS and Azure sits somewhere in between: you get dedicated infrastructure without managing the physical hardware. For enterprises exploring AWS architecture optimization services for enterprises, this is often where the cost conversation starts.
Customization and Fine-Tuning for Business-Specific Use Cases
General-purpose models are good. Models fine-tuned on your domain are better. A legal firm’s contract review tool performs differently when trained on actual contract language versus generic text. Same with financial analysis, medical coding, or customer support in a highly regulated industry.
Private deployment makes ongoing fine-tuning feasible because you control:
- The training pipeline and data
- The iteration and evaluation cycle
- Model versioning and rollback
If you want to go deeper on this, the post on LLM fine-tuning techniques covers the practical options in detail.
Private LLM Deployment Architectures Explained
Cloud vs On-Prem vs Hybrid LLM Deployment Models
| Factor | Cloud (AWS/Azure) | On-Premises | Hybrid |
| Setup Time | Days to weeks | Months | Weeks to months |
| Capital Cost | Low (OpEx) | High (CapEx) | Medium |
| Data Control | High (with private config) | Maximum | High |
| Scalability | Very high | Limited by hardware | High |
| Compliance | Strong | Maximum | Strong |
| Latency | Low to medium | Low | Variable |
| Maintenance | Managed | In-house | Shared |
Key Infrastructure Requirements for Enterprise LLMs
Before picking a deployment model, you need to have these covered:
- GPU compute — NVIDIA A100S or H100S for serious workloads
- High-bandwidth storage for model weights and context (a 70B model in FP16 alone is ~140GB)
- Low-latency networking between inference nodes — InfiniBand or high-speed Ethernet for multi-node setups
- Orchestration layer — Kubernetes in almost every production deployment
- Inference endpoint security — access controls, anomaly detection, and mTLS
- Monitoring and audit logging — GPU utilization, latency percentiles, and per-request traceability
How to Deploy Private LLMs on AWS (Architecture + Services)
AWS Services for LLM Deployment: EC2, SageMaker, Bedrock, EKS
AWS gives you several entry points depending on how much control you want versus how much you want AWS to manage:
- Amazon Bedrock — Easiest path for most enterprises. Provides access to foundation models (Anthropic Claude, Llama, Titan) within your AWS account, with data isolation and no model training on your inputs. The bedrock security and privacy architecture maps cleanly onto most enterprise security requirements.
- Amazon SageMaker — More control. Host your own model, run fine-tuning jobs, and manage the full inference pipeline. The right choice when Bedrock’s model selection doesn’t cover your needs or when you need custom inference logic. For event-driven inference triggers and pipeline automation, AWS Lambda experts can wire up the surrounding architecture cleanly.
- EC2 with GPU instances (P4, P5, G5) — Maximum flexibility, maximum operational overhead. You bring your own model and serving stack and manage everything yourself.
- EKS (Elastic Kubernetes Service) — Sits underneath most serious AWS LLM deployments, handling orchestration, autoscaling, and rolling updates.
Advantages and Limitations of AWS-Based LLM Deployment
| Advantages | Mature GPU instance catalog, Bedrock for managed deployment, strong compliance tooling, and global regions for data residency |
| Limitations | Complex IAM configuration, cost at high scale, vendor dependency for managed services |
We've deployed private LLMs across AWS, Azure, and hybrid environments. Let's find the right architecture for your requirements.
Get StartedHow to Deploy Private LLMs on Azure (Enterprise AI Stack Guide)
Azure Services for LLM Deployment: Azure OpenAI, AKS, Azure ML
- Azure OpenAI Service — GPT-4 and other OpenAI models deployed within your Azure subscription. Private endpoint configuration keeps traffic off the public internet. Microsoft’s data and privacy commitments are specific: your prompts aren’t used for training, and you control content filtering and access policies.
- Azure Machine Learning — Full MLOps pipeline, model registry, managed endpoints, and experiment tracking. Azure’s equivalent of SageMaker.
- AKS (Azure Kubernetes Service) — Handles orchestration with tight integration into Azure AD for access control, which matters in enterprises already running on Microsoft’s identity infrastructure.
Teams working on cloud app development on AWS quickly find that LLM workloads introduce infrastructure patterns that don’t exist in standard web application deployments — GPU scheduling, model versioning, and inference optimization all require deliberate design decisions upfront. If you’re looking to hire AWS cloud engineers who’ve worked through these architectures, that prior experience is a real differentiator.
Enterprise Integration Capabilities in Azure AI Ecosystem
Azure’s real advantage for many enterprises isn’t the AI services in isolation — it’s how they connect to existing Microsoft infrastructure:
- Active Directory for Identity and Access Control of AI Services
- Teams and SharePoint Integration for AI-Powered Internal Tools
- Dynamics Integration for CRM-Based AI Flows
- Native Support of Enterprise Azure AI Services Without Cross-Vendor Complexity
Developers developing on .NET have specific options here. The Azure AI SDK for .NET, the ability to implement foundational AI models in .NET, and a consistent security model across the stack makes the full-stack picture cleaner than mixing vendor ecosystems. If you’re looking to build AI applications with .NET and Azure with unified identity and compliance coverage, Azure is the easier path in Microsoft-heavy organizations.
Advantages and Limitations of Azure LLM Deployment
| Advantages | Azure OpenAI private deployment, deep Microsoft ecosystem integration, strong enterprise identity controls, solid compliance coverage |
| Limitations | Fewer open-source model options natively, can be complex to configure for non-Microsoft workloads |
On-Premise Private LLM Deployment: Infrastructure and Setup Guide
GPU Clusters and Hardware Requirements for LLMs
On-premise deployment starts with hardware sizing:
- 7B parameter models: For 7B parameter models, one NVIDIA A100 can support not only development but also moderate production demands.
- 70B parameter models: Requires multi-GPU nodes, typically 8 GPUs per server, which are either NVIDIA A100 or H100
- Storage: Using NVMe SSD for model weights. A 70B model requires ~140GB of storage for the model weights alone if it’s in FP16.
- Networking: InfiniBand or 100GbE for inter-node communication
- CPU and RAM: Enough headroom so that preprocessing never becomes the bottleneck
The NVIDIA AI Enterprise deployment guide covers the full hardware and software stack for production setups.
Storage, Networking, and High-Performance Data Pipelines
Your storage layer needs to handle concurrent reads from multiple inference workers, fast model weight loading on cold starts, and high-throughput vector retrieval for RAG pipelines.
On-prem actually has a latency edge here; you control the physical proximity between your vector store and inference endpoints, eliminating the unpredictable network hops that cloud deployments can’t fully avoid.
Data pipelines need the same treatment as any latency-sensitive system: tight control over serialization overhead, async processing, and connection pooling.
Kubernetes-Based LLM Deployment on On-Prem Infrastructure
Kubernetes is the default orchestration layer for a reason. It gives you:
- GPU resource allocation for inference pods
- Rolling updates without downtime
- Autoscaling based on queue depth
- Automated pod recovery and health checks
- Namespace-level isolation for multi-tenant scenarios
The pattern of running vLLM or TensorRT-LLM in containers on top of K8s is now well established.
Model Serving and Inference Optimization
Two frameworks dominate:
- vLLM: Best for flexibility, supports PagedAttention, continuous batching, and streaming. Supports all hardware vendors.
- TensorRT-LLM: Only supports NVIDIA, but is substantially faster. Kernel fusion and quantization reduce latency by 30-50% on H100 hardware.
High-volume, latency-sensitive workloads favor TensorRT-LLM. For generative AI workflow automation at scale, it often wins on throughput. Everything else, vLLM is the safer default.
Security and Access Control in On-Prem AI Systems
Full control requires deliberate execution. The baseline:
- mTLS between all internal services
- Role-based access control for inference endpoints
- Secrets management for model weights and credentials
- Immutable audit logs for every inference call
- Network segmentation of the GPU cluster
The prompt-accepting endpoint is an attack surface. Treat it like one.
Monitoring, Logging, and Performance Management
Monitor GPU utilization per node, inference latency at p50/p95/p99, queue depth, memory, and error rates. Prometheus and Grafana are good at that. Log every inference call with user identity, model version, latency, and token count.
Data Sovereignty and Full Control Benefits
The biggest on-prem benefit: your data never leaves your building. For healthcare, defence and financial services in certain jurisdictions, this isn’t a preference; it’s a requirement. Sovereign AI is now a serious policy term, with the EU, UAE, and Australia all developing frameworks that treat AI processing location as carefully as data residency.
Hybrid LLM Deployment Models: Combining Cloud and On-Prem
Hybrid isn’t a compromise for many enterprises; it’s the most rational architecture. The general pattern: keep sensitive workloads on-prem, run lower-sensitivity or burst workloads in the cloud, connect the two with private network links.
Hybrid Architecture Patterns for Enterprise AI
- Split by data sensitivity – Clinical data processing on-prem, administrative AI workflows on Azure OpenAI with private endpoints
- Split by workload type- Fine-tuning on-prem (where training data is most sensitive), serving on cloud (where you need elastic scale)
- Burst model- On-prem handles steady-state load, cloud absorbs overnight batch jobs or traffic spikes
- Federated inference- Same model deployed in multiple locations, routing based on data residency requirements
Real-World Use Cases of Hybrid LLM Deployment
- Banks running credit risk models on-prem while using cloud LLMs for customer-facing applications; the same architecture pattern used when architecting enterprise-grade banking web platforms, where data classification drives infrastructure decisions
- Healthcare systems keep clinical NLP on-prem while using managed AI for administrative workflows
- Manufacturers running process optimization models on factory infrastructure while using cloud AI for supply chain forecasting
Cloud migration projects increasingly have to account for these hybrid patterns rather than assuming a full cloud-first model.
Security, Compliance, and Governance in Private LLM Deployments
Data Isolation and Multi-Tenant Security Strategies
If there are various business units or clients who share the LLM infrastructure, isolation is no longer optional. The approach by sensitivity level:
- Namespace-level isolation in Kubernetes – baseline for internal multi-team deployments
- Inference endpoints per tenant – more isolation, slightly more overhead
- Separate model instances per tenant – most expensive, but unambiguous isolation for regulated environments
Access Control, Monitoring, and Audit Readiness
Every interaction with your LLM infrastructure should be traceable back to a given user or service account. What that means in practice:
- Centralized identity management, tied into your existing directory (AD, Okta, etc.)
- Per-request logging of user identity, timestamp, model version, and token counts
- Immutable audit trail storage (write once, tamper-evident)
- Anomaly detection and automated alerting
- Role-based access control, differentiating between management access and query
If your team needs help structuring this, enterprise AI consulting services can improve the compliance design work significantly.
Meeting Global Compliance Standards (GDPR, HIPAA, etc.)
Key frameworks and what they require from your LLM infrastructure:
- GDPR- Data residency within the EU, right to erasure, documented data processing agreements
- HIPAA- Audit Logs, Access Controls, Encryption of data at rest and in transit, BAAs with any Cloud Providers
- EU AI Act- Human Oversight Mechanisms, Risk Classification, Transparency Documentation for High-Risk Systems
- NIST AI RMF- Vendor-Neutral Framework for Mapping to Multiple Compliance Requirements
- SOC 2/ISO 27001- Documentation of Security Controls, Readiness for Third-Party Audits
Common Challenges in Private LLM Deployment (And How to Solve Them)
Managing Infrastructure Complexity
Production LLMs aren’t like typical web applications. GPU scheduling, model versioning, inference optimization, and observability all stack up before you’ve written a single line of application logic.
Teams building from scratch lose months they don’t need to. Bringing in engineers who’ve done this before, whether embedded dedicated AI developers or a DevOps outsourcing partner with prior LLM infrastructure experience, cuts that timeline significantly.
Addressing AI Talent and Skill Gaps
The skills you need rarely exist in one person. MLOps, GPU infrastructure, LLM fine-tuning, enterprise security, and compliance all pulled into one role. Most enterprises close this gap through a mix of internal upskilling and external support. Engaging a partner for custom machine learning development services fills immediate gaps without stalling your roadmap.
Controlling Costs at Scale
GPU instances are expensive. Idle GPU instances are just expensive with nothing to show for it. The practical cost levers:
- Autoscaling with scaling down during off-hours
- Quantization to reduce the size of the model
- Batch processing for non-latency-critical workloads
- Spot/preemptible for fault-tolerant workloads
- Quota management for runaway inference costs
Enterprise DevOps services that bake cost optimization into the engagement tend to pay for themselves fast.
AI developers, DevOps engineers, and cloud architects, ready to build alongside your team.
Hire NowHow to Choose the Right Private LLM Deployment Strategy for Your Enterprise
Getting the deployment model right starts before you touch a single line of infrastructure code. The enterprises that struggle usually skipped the requirements work — they picked a platform based on familiarity or vendor pressure and built themselves into a corner. Here’s a structured way to avoid that.
Decision Checklist: Data Residency, Team Readiness, Workload Volume, Budget
Work through these before committing to any architecture:
Data Residency and Compliance
- Are there regulations that place restrictions on where data is processed? (GDPR, HIPAA, UAE data standards, Australian privacy laws)
- Do you have any customers or contracts that place requirements on data handling and processing?
- Are you required to support audit requirements that necessitate immutable logs and traceable inference calls?
- Does your legal team require air-gapped isolation, or is a private cloud endpoint acceptable?
Team Readiness
- Do you have any engineers who have experience using GPU clusters in production environments?
- Is your DevOps team familiar with using Kubernetes for ML workloads, or is this new territory for them?
- Do you have Python developers for private LLM, who are familiar with frameworks like vLLM or LangChain, or will you need to bring that experience in?
- Do you have the internal capacity to manage versioning, fine-tuning, and incident response for an AI system?
If the answer to most of the questions is NO, then consider whether your budget allows you to bring in external support, either by choosing to hire dedicated AI developers or by working with a managed service provider.
Workload Volume and Latency
- How many inference requests per day are you planning for at steady state? At peak?
- Do you have real-time latency requirements (sub-200ms), or is batch processing acceptable?
- Is your workload bursty or consistent? Bursty workloads favor cloud elasticity; consistent high-volume workloads favor on-prem economics.
- Will you be running RAG pipelines? If it’s yes, where does your knowledge base live, and how does that affect co-location decisions?
Budget and Time Horizon
- Are you optimizing for low upfront cost (cloud OpEx) or lower long-term cost (on-prem CapEx)?
- What’s your timeline to first production deployment? On-prem procurement alone can take 3–6 months.
- Have you factored in ongoing operational costs — engineering time, monitoring tools, license fees, and GPU maintenance?
- Is this a strategic long-term AI infrastructure investment, or a time-limited pilot?
Decision Matrix: AWS vs Azure vs On-Prem vs Hybrid by Use Case
| Use Case | Best Fit | Why |
| Regulated healthcare data (PHI) | On-Prem or Hybrid | Air-gapped control; HIPAA audit trail requirements |
| Financial services — customer-facing AI | Azure or AWS (private) | Elastic scale, private endpoints, fast deployment |
| Legal document analysis (sensitive M&A) | On-Prem | Data never leaves your environment |
| Internal productivity tools (HR, IT support) | AWS Bedrock or Azure OpenAI | Low sensitivity, fast time-to-value |
| Government/defense workloads | On-Prem (air-gapped) | Sovereign data requirements, classification controls |
| Multi-region enterprise with mixed sensitivity | Hybrid | Route by data type; optimize cost and compliance |
| Startup or early-stage enterprise AI | AWS or Azure | Managed services, minimal infra overhead |
| High-volume inference at scale (>10M calls/day) | On-Prem or Hybrid | Economics favor owned compute at this volume |
| Fine-tuning on proprietary datasets | On-Prem or private cloud | Training data should never leave your environment |
| Rapid prototyping/proof of concept | AWS Bedrock or Azure OpenAI | Deploy in hours, iterate quickly, no hardware procurement |
This matrix isn’t exhaustive, but it covers the patterns that come up most often. If your use case spans multiple rows, hybridization is almost always the answer, and building a custom API integration that abstracts the underlying platform is what makes a hybrid architecture actually manageable.

Questions to Ask Your AI Infrastructure Vendor Before Committing
Most vendor conversations stay at the surface level. These questions will tell you whether a vendor actually understands enterprise AI infrastructure or is selling you a demo:
On Data and Security
- Where does our data go when a prompt is processed? Can you show us the network path?
- Is our data ever used to train or improve shared models?
- What happens to our data if we terminate the contract?
- Can you provide SOC 2 Type II or ISO 27001 audit reports on request?
- What’s your data breach notification timeline?
On Compliance and Governance
- Which compliance frameworks do you formally support, with documentation?
- Can you support data residency in specific geographies?
- Will you sign a BAA (HIPAA) or DPA (GDPR)?
- Do model updates affect our compliance posture — and will we get advance notice?
On Infrastructure and Performance
- What hardware is behind the GPUs in your managed endpoints? Are we able to get dedicated capacity?
- What are your SLAs around inference latency and uptime?
- Is there a risk of throttling when we need the most capacity?
- Are we able to provide our own weights that are fine-tuned, or are we limited to your existing models?
- How long is a given version of the model guaranteed to be available?
On Vendor Lock-In and Exit
- Can we export our fine-tuned model weights if we leave?
- What does migration look like if we move to on-prem or another provider?
- Are your APIs compatible with open standards like OpenAI-compatible endpoints?
The vendors who can answer all of these clearly, in writing, are the ones worth working with. The ones who deflect or get vague on data handling specifics are telling you something important.
Future Trends in Private LLM Infrastructure and Deployment

Edge AI and Smaller, Efficient Language Models
Small models are changing the economics of private deployment. A fine-tuned 7B can outperform a general-purpose 70B on a task at a small fraction of the cost. Edge AI running models on-device or edge servers is now practical for latency-sensitive workloads where cloud round-trips are too slow. Quantized models (4-bit, 8-bit) have reached production quality, cutting hardware requirements significantly.
Growth of Open-Source LLM Ecosystems
Llama, Mistral, and Falcon are genuinely competitive for most enterprise use cases. Open weights combined with private infrastructure is fast becoming the default for enterprises that want flexibility without vendor lock-in. LangChain’s enterprise deployment patterns have matured enough to support production-grade orchestration on top of these models.
Multi-Cloud and Vendor-Agnostic AI Strategies
Enterprises are building LLM infrastructure to be portable, running the same serving stack (vLLM, LangChain) across AWS, Azure, and on-prem, standardizing on Kubernetes as the common orchestration layer, and using custom API integration to abstract the underlying platform from application code. No single vendor’s pricing decision should be existential.
Teams working with data visualization and reporting alongside inference workloads, particularly those using experienced AWS QuickSight developers, benefit most from this vendor-agnostic approach, since reporting infrastructure can stay cloud-native while sensitive inference stays private.
Why Choose CMARIX for Enterprise Private LLM Deployment
CMARIX has been building enterprise AI systems across healthcare, finance, and manufacturing, including private LLM deployments on AWS, Azure, and on-prem GPU clusters. The team covers the full stack:
- Infrastructure architecture and cloud configuration
- Model fine-tuning and evaluation pipelines
- Custom generative AI development services
- Compliance design and audit readiness
- Ongoing managed support and optimization
Whether you need AI software development solutions from the ground up or a specialized team to handle a specific layer of your LLM infrastructure, the engagement model adapts to where you are.
Conclusion: How to Choose the Right Private LLM Deployment Strategy
No universal right answer exists, but the signals are clear.
- Choose cloud if you need speed, managed infrastructure, and private endpoints to meet your compliance needs.
- Choose on-prem if your data sovereignty needs are non-negotiable, if you are at scale, or if you need air-gapped isolation.
- Choose a hybrid if your workloads are mixed and you are balancing security against cost.
The enterprises that got this right didn’t pick the “best” architecture in the abstract; they matched their actual requirements to the model that fit. And for organizations already running on Microsoft infrastructure, Microsoft development services for enterprises can bridge the gap between existing systems and a production-ready private LLM deployment.
FAQs: Enterprise Private LLM Deployment on AWS, Azure, and On-Prem
What is the primary advantage of deploying a Private LLM on AWS or Azure?
Data control without sacrificing scalability. Both platforms support fully private configurations; your data stays within your cloud account, never touches shared model training, and you get enterprise-grade audit tooling built in.
When should an enterprise choose On-Premise infrastructure for AI?
When regulatory requirements demand it, when you’re at a scale where owned hardware beats cloud pricing, or when you need air-trapped isolation that cloud deployments can’t satisfy.
How do enterprises ensure data privacy when using Azure OpenAI?
Private endpoints, VNet integration, disabled content logging, and Azure AD-based access controls. Microsoft’s commitments on this are documented specifically; your prompts are not used for model training, and traffic stays within your Azure environment.
Can private LLMs be deployed in a Hybrid Cloud model?
Yes, and it’s increasingly common. Sensitive workloads run on-prem or in a private cloud environment, while less sensitive or burst workloads run on public cloud. Well, the key is consistent orchestration and security policy across both environments.
What technical stack is needed to manage a Private LLM on-premise?
* NVIDIA GPUs (A100 or H100 series for production workloads)
* Kubernetes for orchestration
* vLLM or TensorRT-LLM for model serving
* Prometheus and Grafana for monitoring
* A vector database if you’re building RAG pipelines
* InfiniBand or high-speed Ethernet for multi-node configurations
How does Sovereign AI impact deployment choices in 2026?
Significantly. Countries across the EU, the Middle East, and the Asia-Pacific are establishing requirements around where AI processing can occur and who can access that data. For multinational enterprises, this means deployment architectures that can satisfy multiple jurisdictions, often through regional on-prem deployments or cloud regions with strict data residency guarantees.