

Quick Summary: Discover how LLM fine-tuning models can turn ordinary AI into a true expert for your business. Learn simple ways to make the model smarter, accurate and more in tune with your goals using methods like LoRA, PEFT and instruction tuning.
Do you remember the first time you used a Large Language Model(LLM) like GPT-4 or Claude? The raw power was obvious. These models are trained on petabytes of internet data, giving them incredible general knowledge. But if you’ve tried to use a base model for a very specific, specialized task, you will quickly hit a wall. Because the answers feel generic, the tone is off, and the accuracy is shaky.
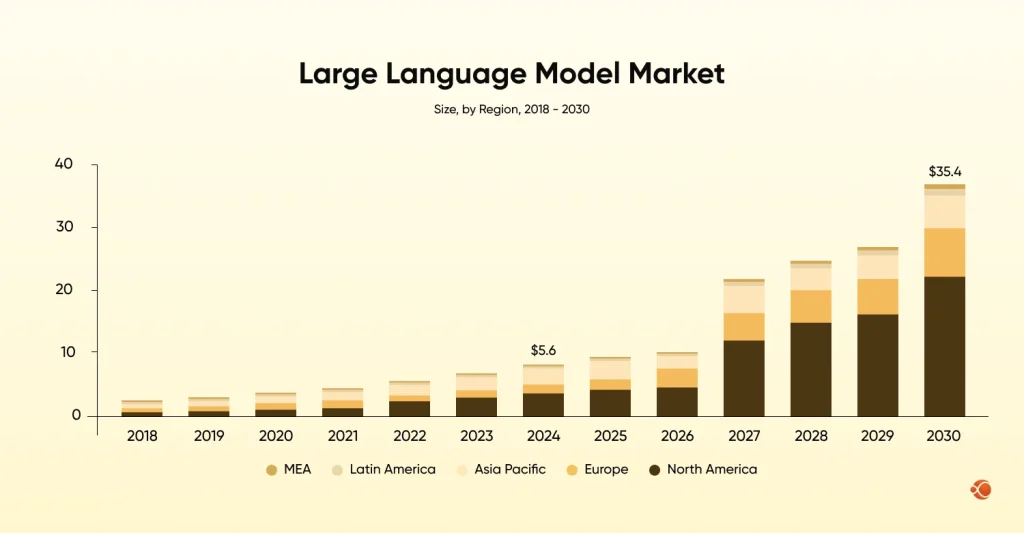
This gap between general capability and specific, high-stakes utility is why LLM fine-tuning is no longer a luxury; it’s a necessity for any business serious about custom LLM development in 2025. The global market size of LLM models was estimated at USD 5,617.4 million in 2024, and it is projected to reach USD 35,434.4 billion by 2030. Also, the CAGR of 36.9% from 2025 to 2030.
In this complete guide, we’ll break down everything you need to know about fine-tuning in LLM: What it is, the different methods available, how to prepare your data, and a step-by-step plan for fine-tuning GPT models successfully.
What Fine-Tuning Is and Why It Matters for LLMs
At its heart, fine-tuning is a second stage of training. A base LLM is first trained in an expensive, time-consuming process called pre-training. This phase teaches the model its language skills by predicting the next word in massive amounts of text.
LLM fine-tuning takes that pre-trained model and continues the training process using a much smaller, highly focused, high-quality dataset. Instead of learning general language, it learns specific patterns, styles, and facts relevant to a particular domain or task. The model adjusts its internal weights just enough to specialize.
Benefits of Fine-Tuning Over Base Models
Why go through the effort of fine-tuning LLM models when you can just use a powerful base model? The benefits center on performance, relevance, and efficiency.
- The model learns precise, domain-specific facts and terminology, reducing general guesses and hallucinations.
- The model adopts a specific brand tone, voice, or compliance style, making sure consistent output.
- Allows the model to be trained to strictly avoid generating inappropriate or non-compliant content specific to an industry.
Different Types of LLM Fine-Tuning Explained
The term “LLM Fine-Tuning” is a broad umbrella that covers several distinct strategies. The right method depends entirely on your goal, the size of your dataset, and your available compute resources.
Full Fine-Tuning
Full fine-tuning is the most comprehensive approach. It updates all the parameters (weights) in the base LLM using your new dataset.
- Pros: Achieves the highest possible performance and maximum domain adaptation, as the model is fully customized.
- Cons: Requires significant GPU resources (often multiple high-end GPUs like A100s), a large amount of high-quality data, and takes the longest time. This is also known as a very high cost of fine-tuning LLM.
Parameter-Efficient Fine-Tuning (PEFT)
PEFT methods are revolutionary because they update only a small fraction of the model’s parameters. This reduces the computational requirements and memory, making fine-tuning GPT models and other LLMs accessible to more teams.
1. LoRA (Low-Rank Adaptation)
LoRA trains and injects small, low-rank matrices into the model layers while keeping the core weights frozen. This is the most popular method because it drastically reduces the number of trainable parameters and memory footprint. This efficiency enables powerful models to be trained on accessible hardware like a single consumer GPU, resulting in tiny, easily swappable adapter files.
2. Adapter Tuning
This technique inserts small “bottleneck” adapters or modules between the frozen base model’s layers, training only the adapter weights. This is ideal for multi-task learning, as you can create a small adapter for each specific task and quickly swap them out without reloading the entire base model.
3. Prefix Tuning
Prefix tuning keeps the entire LLM frozen. Instead of modifying weights, it learns a sequence of virtual “prefix tokens” that are prepended to the input prompt to guide the frozen model’s output. This provides extreme efficiency and is highly effective for tasks like summarization and classification.
Instruction Tuning
Instruction tuning is the way of training an LLM on a collection of structured, high-quality, task-agnostic instruction-output pairs. This process teaches the model to follow human instructions, making it more capable of acting as an assistant or chatbot. Many artificial intelligence development services now prioritize instruction tuning as a cost-effective method to enhance model utility without extensive computational overhead.
- Goal: To improve the model’s generalization capabilities and its ability to zero-shot (perform a task it wasn’t specifically trained on, just by following a prompt).
- Key Datasets: Often uses curated datasets like Flan, Alpaca, or custom conversational data.
Reinforcement Learning from Human Feedback (RLHF)
RLHF is the methodology that takes Instruction Tuning to the next level, and it’s a standard for creating models like ChatGPT.
- How it works: After instruction tuning, human reviewers rank multiple model outputs for quality, helpfulness, and safety. This human feedback is used to train a Reward Model. The LLM is then optimized using reinforcement learning to generate responses that maximize the predicted score from this Reward Model.
- Goal: Aligning output style and behavior to human preferences and significantly enhancing safety and truthfulness.
Data Preparation for LLM Fine-Tuning: Best Practices and Strategies
Even the most sophisticated LLM fine-tuning techniques will fail if the underlying data is poor. Data is the fuel, and in fine-tuning, you need high-octane fuel, not muddy water. Garbage in truly is garbage out, and this is the most common reason for project failure.
Importance of High-Quality, Task-Specific Datasets
When models are pre-trained, they see trillions of words; while fine-tuning, they might only see thousands or tens of thousands. This means that every example counts, and the data must be perfectly aligned with the desired output.
For instance, if you’re trying to build a customer support bot, your fine-tuning dataset shouldn’t contain general Wikipedia articles; it needs real-world examples of customer questions and the exact, preferred company responses. This guarantees domain-specific fine-tuning success.
Formatting Input-Output Pairs for Fine-Tuning
The structure of your data depends heavily on the type of fine-tuning you choose:
- Instruction Tuning/Chat: The model is trained on a sequence of turns that mimic a conversation or a single instruction.
- Format: {“instruction”: “Summarize this legal brief.”, “output”: “The brief argues…”} or a multi-turn array: [{“role”: “user”, “content”: “What is the return policy?”}, {“role”: “assistant”, “content”: “Our policy allows…”}]
- Classification/Extraction: The input text is paired with the required label or extracted data.
- Format: {“text”: “The client paid on 01/01/2025.”, “label”: “Payment Date: 01/01/2025”}
The key is consistency. Every data point must follow the same schema so the model can reliably learn the input-to-output mapping.
Cleaning, Deduplication, and Labeling Strategies
A clean dataset is a performant model.
- Cleaning and Deduplication: Remove identical or near-identical examples. Duplicates lead to overfitting or biasing the model. Clean up formatting, irrelevant metadata and irrelevant metadata that might distract the model.
- Labeling and Quality Assurance: If you are using human annotators (which is common for instruction tuning), implement a quality assurance loop. Use consensus checks, have multiple labels review the same data, and ensure labels are consistent. Inconsistent labeling will confuse the model and severely limit performance.
- Domain-Specific Data Preparation Tips: In case your goal is custom LLM development, then you must prioritize vocabulary. Collect glossaries, internal documentation and industry-specific manuals. Convert these into Q&A pairs or instructional prompts. This rapidly injects the necessary technical language into the LLM’s knowledge base without requiring huge amounts of general text.
How to Fine-Tune GPT Models: Step-by-Step Guide

While the specifics of tooling change, the fundamental process for fine-tuning GPT models and other transformer architectures remains the same.
Step-1 Define the Use Case and Success Criteria
Before starting to write code, define what success looks like.
- Specify Tasks: Is it for chat, summarization, or technical classification?
- Target Users: Are they internal experts or external customers? This dictates complexity and tone.
- Measurable Goals: This is critical. A goal should be quantifiable.
Step-2 Gather and Curate a High-Quality Dataset
At this stage, most of the effort goes. Before committing significant resources to full-scale training, many organizations benefit from AI PoC development services to validate the approach with a small dataset and prove ROI. Focus on representativeness. Your test set must accurately reflect the real-world inputs your model will see in production.
Step-3 Prepare and Preprocess the Data
- Tokenization: Convert your text data into numerical tokens that the LLM understands, using the exact same tokenizer that was used for the base model.
- Splits: Create a Train set (e.g., 80%) for teaching, a Validation set (e.g., 10%) for monitoring performance during training and catching overfitting, and a final Test set (e.g., 10%) for final, unbiased evaluation.
- Prompt Templates: For instruction tuning, wrap your input and output in a structured template (e.g., [INST] {instruction} [/INST] {output}) to guide the model’s behavior.
Step-4 Choose the Base Model and Fine-Tuning Method
- Base Model: Smaller models (like 7B or 8B parameters) are faster and cheaper to fine-tune. Larger models (like 70B) often have stronger reasoning before tuning. Choose the smallest model that meets your performance goals.
- Method: For resource efficiency, LoRA or QLoRA are usually the best starting points for LLM Fine-Tuning. Use Full Fine-Tuning only if PEFT methods prove insufficient for your target accuracy.
Step-5 Set Up Environment, Tooling, and Data Pipeline
You need the right tools for Large Language Model optimization.
- Compute: Provision GPUs. Cloud services (AWS, Azure, GCP) or dedicated hardware.
- Libraries: Install essential tools like Hugging Face Transformers for model access, PEFT for efficient methods, and sometimes DeepSpeed or FSDP for distributed training if doing full fine-tuning.
- Data Pipeline: Use libraries like Datasets or pure Python/Pandas for efficient data loading, augmentation, and reproducible data splitting.
Step-6 Design Your Training Plan and Hyperparameters
Hyperparameters control the training process and affect the results:
- Batch Size: Use the larger batch size that your GPU can handle. Larger batches help the model generalize much better.
- Number of Epochs: 1 to 3 epochs is enough to avoid overfitting, in case of Fine-Tuning.
- Learning Rate: The most important setting. Start low and use a learning rate scheduler to reduce it over time.
Step-7 Run Training with Validation
At this stage, start training; this is a monitoring phase.
- Monitor Loss: The training loss should steadily decrease.
- Monitor Validation Metrics: The metric you defined in Step 1 (e.g., F1, Accuracy) on the validation set is your key indicator. If training loss continues to fall but validation metrics plateau or get worse, stop immediately (this is early stopping), as the model is starting to overfit.
- Checkpointing: Save the model weights (checkpoints) periodically so you don’t lose progress and can revert to the best-performing version.
Step-8 Evaluate Thoroughly
Use your held-out Test Set of the data the model has never seen, to get the final, true picture of performance.
- Automated Metrics: Calculate ROUGE for summarization, F1/Accuracy for classification, and BLEU/METEOR for generation quality.
- Human Review: Automated metrics can be misleading. Always include a small human review loop, especially for safety, tone, and factual accuracy checks.
Step-9 Refine and Iterate
If your metrics don’t meet the target from Step 1, you must iterate. The most common adjustments are:
- More/Cleaner Data: Always the highest leverage change.
- Hyperparameter Tuning: Adjust the learning rate or batch size.
- Different Method: Move from LoRA to Full Fine-Tuning, or try a different Prompt Template.
Step-10 Prepare for Deployment and Monitoring
- Export: Export the final, best-performing model checkpoint.
- Optimizations: Use tools like quantization (e.g., 4-bit/8-bit QLoRA) and compiler-level optimizations (like TorchScript) to reduce latency and memory footprint for inference.
- Monitoring: Set up live tracking for performance drift (where real-world accuracy degrades over time), errors, and safety incidents.
LLM Fine-Tuning Techniques Explained: LoRA, PEFT, QLoRA, and Instruction Tuning
Understanding the differences between full fine-tuning and parameter-efficient methods is key to controlling the cost of fine tuning LLM.
Full Model Fine-Tuning vs. Parameter-Efficient Fine-Tuning (PEFT)
- Full Fine-Tuning updates all billions of model parameters, requiring huge GPU resources for days or weeks, providing maximum performance but risking high cost.
- PEFT(Parameter-Efficient Fine-Tuning), like LoRA, freezes most parameters and trains only a small, efficient subset. This drastically reduces hardware needs, speeds up training to hours, and is highly preferred for its portability and efficiency.
QLoRA: The Memory Saver
QLoRA (Quantized Low-Rank Adaptation) is an advanced LLM fine tuning technique that combines LoRA with 4-bit quantization. By loading the base model at 4-bit precision, it reduces the memory footprint dramatically. This is the standard, accessible method that allows massive models (e.g., 65B parameters) to be fine-tuned on single, high-memory GPUs.
Domain Adaptation vs. Instruction Tuning
Domain Adaptation teaches the model a specific vocabulary (e.g., legal or medical jargon) by training on relevant documents to improve factual understanding. Instruction Tuning focuses on teaching the model how to behave, improving its ability to follow commands, maintain a specific tone, and adhere to required output formats.
Overfitting Prevention and Generalization
Overfitting is when the model memorizes the training data. The most effective countermeasure is Early Stopping, which halts training when performance on a separate validation set begins to decline. Other strategies include maintaining a Low Learning Rate to make small, careful parameter adjustments and using Data Augmentation to increase the dataset’s diversity.
Tools and Frameworks
The modern LLM fine-tuning workflow is standardized by the Hugging Face ecosystem. The Transformers library provides model access, while the PEFT Library simplifies implementing efficient methods like LoRA. For large-scale full fine-tuning, specialized tools like DeepSpeed are used. When transitioning from training to production, implementing trained AI models becomes a critical phase that requires expertise in model serving, API design, and infrastructure optimization, especially when leveraging lightweight AI techniques for startups.
RAG vs. LLM Fine-Tuning: Which Approach Delivers the Best Results?
A frequent question is: Should I use Retrieval-Augmented Generation (RAG) or LLM Fine-Tuning?
| Feature | Fine-Tuning | RAG (Retrieval-Augmented Generation) |
| Purpose | Teaches the model a new skill or style. | Provides the model with new knowledge at runtime. |
| Data Type | High-quality (instruction/format) pairs. | Large, proprietary documents/databases. |
| Model Change | Permanent change to the model’s weights. | No change to the model; knowledge is external. |
| Accuracy | High, but only for tasks seen in the training data. | High, with verifiable sources from the retrieved documents. |
| Cost | High initial cost (training). | Low-cost per query (API calls/retrieval). |
The Best Approach:
- Use RAG when the knowledge base changes constantly or when verifiable citation is needed.
- Use LLM fine-tuning when you need to change the model’s behavior, tone or ability to execute a specific complex function.
In many high-performance enterprise scenarios, the answer is both: fine tune the model for right instruction. Generative AI integration services make sure that your fine-tuned model connects smoothly with existing workflows, APIs, and business for the right instruction-following behavior, and use RAG for accurate, up-to-date knowledge retrieval.
Best Practices for LLM Fine-Tuning: Tips to Improve Accuracy and Efficiency
Choosing the Right Base Model for Your Task
Start by thinking about your task. For general chat/reasoning, a GPT-family or Llama-family model is best. For code generation, a specialized base model like Code Llama should be your starting point. You don’t just pick a large model; you pick a relevant pre-trained model to get a head start.
If internal expertise is limited, organizations should consider whether to hire AI developers with specialized experience in transformer architectures and training pipelines to ensure project success.
Ensuring Clean, Unbiased, and High-Quality Datasets
Always spend disproportionately more time on data preparation than on training. A $10,000 fine-tuning run on bad data is a waste. Furthermore, actively audit your data for bias. If your training data contains biases, your model will amplify them, which directly impacts improving safety and compliance.
Evaluating Models with Automated Metrics and Human Feedback
Don’t just rely on a single metric. If you’re building a summarization tool, use ROUGE (Recall-Oriented Understudy for Gisting Evaluation) scores for overlap, but also have humans check if the summary captures the key points and if the tone is appropriate. For tasks like classification, calculate metrics on class-by-class performance to identify and fix areas where the model struggles.
Version Control, Continuous Improvement, and Ethical Considerations
- Version Control: Treat your fine-tuned models and the exact dataset used to create them like code. Log everything using tools like Weights & Biases (W&B) or MLflow for reproducibility.
- Continuous Improvement: The model performance will drift over time as real-world inputs change. Set up a pipeline to continuously collect new, labeled production data to regularly refresh or incrementally fine-tune your model.
- Ethical Considerations: Ensure your model doesn’t generate toxic content, reproduce personal information from the training data, or exhibit bias. Ethical considerations must be baked into your data preparation and evaluation processes from day one.
Real-World Use Cases of LLM Fine-Tuning
1. Domain Adaptation
Turning a general LLM into an expert in an area like financial analysis by training it on thousands of corporate filings.
2. Improving Task Performance
Taking a model that is generally good at classification and making it state-of-the-art at classifying support tickets into 50 specific categories drastically improves efficiency.
3. Aligning Output Style and Behavior
Training a model to strictly adhere to a company’s brand voice, safety protocols, and formatting requirements, for example, a model that only speaks in the style of a formal legal advisor.
4. Enhancing Safety and Compliance
Using RLHF to minimize the chance of the model generating harmful, offensive, or non-compliant content, especially critical in regulated industries like healthcare.
5. Reducing Latency and Cost
Using PEFT to create a custom, high-performance, smaller model for deployment, which leads to lower operational costs per inference and faster response times.
Why Choose CMARIX for Advanced LLM Fine-Tuning and Custom AI Services
CMARIX specializes in advanced AI services, including complete AI LLM fine-tuning services designed to remove the gap between base models and specific business needs. We provide end-to-end solutions, from strategic data preparation and hyperparameter optimization to final deployment and continuous MLOps monitoring.
Our approach focuses on:
- Domain-Specific Adaptation: Leveraging techniques like LoRA and Instruction Tuning to create models that are not just smart, but relevant to your industry jargon and requirements.
- Efficiency: Maximizing performance while controlling the cost of fine tuning LLM through expert use of PEFT and QLoRA techniques.
- Full Lifecycle Support: Covering everything from defining success criteria to implementing monitoring and continuous improvement, making sure your investment yields measurable business value.
Final Words
The era of simply prompting general-purpose LLMs is quickly fading. The future of competitive AI lies in customization and specialization, and LLM fine-tuning is a proven pathway to reform generalized tools into reliable experts that drive quantifiable business results.
To maximize this impact, remember that data is the foundation, so prioritize the quality, consistency, and format of your training data above all else, and always start with resource-efficient methods like LoRA to manage costs.
FAQs on LLM Fine-Tuning
Why is LLM fine-tuning important?
LLM fine-tuning is essential for transforming generic models into tailored, domain-specific tools that deliver higher accuracy, relevance, and brand alignment. It solves the limitations of base models in specialized business applications.
What frameworks are used for fine-tuning LLMs?
Leading frameworks for fine-tuning LLMs include Hugging Face Transformers, PEFT (Parameter-Efficient Fine-Tuning) for methods like LoRA/QLoRA, and DeepSpeed for efficient large-scale training.
How much does fine-tuning an LLM cost?
Fine-tuning costs range from a few hundred dollars (using PEFT on smaller models with a single GPU) to tens of thousands for full fine-tuning of large models requiring multiple high-end GPUs.
Is fine-tuning better than prompt engineering?
Fine-tuning is ideal for teaching new skills and enforcing style, while prompt engineering guides a pre-trained model’s behavior without altering its core parameters; both can be complementary.
What are examples of LLMs that can be fine-tuned?
Popular LLMs for fine-tuning include GPT-3/4, Llama-2/3, Falcon, Mistral, and specialized variants like Code Llama for code-related tasks.
How do you fine-tune LLM models?
Fine-tune an LLM by curating domain-specific data, preprocessing it into consistent input-output pairs, choosing an appropriate base model and efficient tuning method (like LoRA), and running monitored, iterative training using libraries such as Hugging Face Transformers.




