

Quick Summary: Data silos not only limit data accessibility but also delay decision-making and hinder organizations’ ability to extract the maximum value from the data they have. In this article, you will learn about how properly optimized Data Mesh architecture helps companies overcome these obstacles by adopting the right framework, infrastructure, and approaches to creating data products.
Most global enterprises don’t have a data shortage. They have a data access crisis.
Data exists, often in overwhelming volumes, but it lives in isolated systems, controlled by separate teams, formatted for specific tools, and inaccessible to the people who need it most. The supply chain database can’t talk to the demand forecasting model. Finance can’t pull real-time operational data without filing a multi-week pipeline request. Marketing analytics and customer success metrics live in parallel universes with no reliable bridge between them.
This is the enterprise data silo problem, and in 2026, it carries consequences well beyond delayed dashboards.
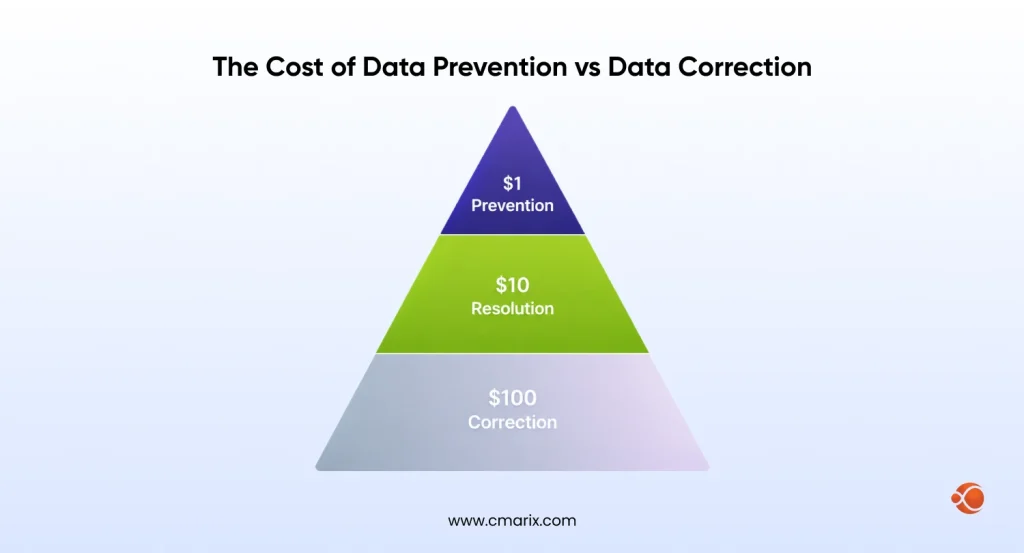
Correcting a data error costs 100 times more than preventing a data issue. This is what a whitepaper by DCI points out, when talking about the cost involved in finding a data problem, and the cost of working with poor data till its found is profoundly more than preventing any data risks to begin with. This just shows the urgency with which organizations need to focus on data structuring and optimization to avoid cumulative billing with expanding databases.
In this article, you will learn everything about Data Mesh, starting from its definition, four key pillars, its benefits over other existing approaches, and the roadmap for implementation in 2026.
Why Centralized Data Architecture Keeps Producing Silos
Before defining the solution, it’s worth being precise about why the problem is architectural, not technical.
A data silo forms when data is created and consumed within a single organizational unit, with no reliable, governed pathway for the rest of the enterprise to access it. The instinctive response has historically been centralization: build a central data warehouse, hire a central engineering team, create pipelines from every source system to one shared repository.
The problem is that centralization doesn’t eliminate silos. It displaces them, and at a global enterprise scale, it creates a different, more persistent failure mode.
Gartner’s enterprise technology research shows the average large enterprise now operates over 900 discrete SaaS and cloud applications simultaneously. Each generates data on its own schedule, in its own format, with its own schema. A central data engineering team, regardless of its size, cannot maintain quality pipelines across all of them. What follows is a predictable cascade:
- Engineering bottlenecks compound: New data consumers only add to the existing bottleneck. Interdisciplinary data queries are subject to lead times of 4 to 7 months. By the time data is delivered, the business question has evolved.
- Domain expertise is stripped from data: Engineers responsible for creating pipelines for logistics data may lack the domain-specific knowledge of logistics teams, leading to degraded data quality and a lack of accountability.
- Accountability evaporates: regulations, data residency requirements, latency issues, and geographic business logic make centralized governance unachievable in practice.
- Global complexity becomes unmanageable due to regulatory requirements, data residency, latency requirements, and differences in business logic across geographies, making centralization theoretically impossible.
Approximately 73% of enterprise data is never analyzed. The organizational machinery designed to make data useful is, at most organizations, making less than a quarter of available data accessible to the people who need it.
The magnitude of this failure exposes what centralized approaches tend to mask: data silos exist because of the organization rather than as a function of the technology. And this is precisely the reason why efforts toward enterprise application integration and data architecture begin to coincide, addressing the same organizational core issue.
What Is Data Mesh Architecture?
The data mesh framework is a decentralized data architecture that leverages four interrelated architectural principles. Data Mesh principles were defined by Zhamak Dehghani, who laid the foundation for the current data mesh philosophy through her groundbreaking work.
The core logic is straightforward: the data quality crisis in large organizations is not a technical failure—it is an organizational one. Centralizing data management separates data ownership from domain knowledge. The teams that understand data most deeply (the domains that create it) have no accountability for it. The teams responsible for it (central engineering) cannot understand it all. Data mesh resolves this by distributing data ownership to the business domains that produce data, while enforcing quality, governance, and interoperability through a shared platform layer.
The result: distributed accountability with centralized governance, the structural combination that makes large-scale, reliable enterprise data management sustainable.
For us at CMARIX, our enterprise data engineering capability has helped enterprises navigate through this transition in the fintech, logistics, and manufacturing industries. The result is always the same: successful implementation leads to 40–60% faster time-to-insights and improved cross-domain data quality within 12 months of going live.
The Four Core Pillars of Data Mesh
1. Domain-Oriented Decentralization
The foundational principle: data ownership belongs to the domain that generates it.
In a centralized architecture, data flows from source systems into a shared repository managed by a central team. Business domain teams in finance, operations, supply chain, and customer success are consumers who submit requests and wait for them to be processed. Ownership is separated from context. Quality is separated from accountability.
In data mesh, each domain owns its data throughout its lifecycle from design for ingestion, transformations, data quality management, access controls, etc. The supply chain owns the supply chain data; customer success owns engagement data, finance owns financial data, etc. Ownership drives accountability, and accountability drives sustainable data quality.
This organizational structure replicates the development of today’s enterprise software solutions: modular, context-bound structures in which quality is a product of ownership rather than curation. The very notion that made microservice architectures scalable is now being leveraged to scale data.
2. Data-as-a-Product (DaaP)
The most important paradigm shift in data mesh thinking: viewing datasets as first-class citizens.
A data product in a mesh must provide:
- Schema defined with versioning and guarantee of backward compatibility
- SLAs for the quality of data (freshness, completeness, and thresholds of accuracy)
- Named ownership – an identified group responsible for the quality and availability
- Discoverability – discoverable within the mesh by authorized consumers
- Changelog – breaking changes documented and migration guidance provided prior to deployment
3. Self-Serve Data Infrastructure as a Platform
If domain teams are expected to take ownership of their data, they need an infrastructure that allows them to do so without needing highly skilled data engineers. The platform layer for that is self-service data infrastructure.
The platform team’s mandate is not to build pipelines; it is to build the tools that enable domain teams to build their own. A mature self-serve platform provides:
- Pipeline templates (golden paths) for common ingestion and transformation patterns
- Schema registry and data catalog for product documentation and consumer discovery
- Compute environments (Spark, dbt, Flink, Databricks) are accessible through self-service configuration.
- Observability tooling pre-integrated at the platform level
- Runtime policy enforcement — governance rules applied automatically, not audited after the fact.
This architectural concept directly translates into a much more general framework for designing distributed computing systems. The rationale for choosing Edge in the comparison of Edge computing vs Cloud computing, by bringing computing power closer to the source of the data instead of aggregating it at one place, is exactly the same rationale that underlies Data Mesh architecture.
4. Federated Computational Governance
Decentralization without governance is fragmentation by another name. Federated computational governance closes the loop.
With federated governance, data policies in the global environment are centrally determined and automatically enforced via the platform layer. Individual domains have the freedom to operate according to the specified policies. In other words, domains get to decide how to create their data products, but not whether they should meet specific quality, privacy, or access-control requirements.
A global mesh’s governance usually entails: taxonomy for data classification, enforcement of privacy laws (GDPR, among others), quality minimums that all data items have to meet before publication, access controls standards, and standards for interoperability of schema languages and event protocols.
Enforcement is machine-driven, not dependent on compliance teams manually auditing hundreds of data products across dozens of domains. A GDPR-compliant European data product and a CCPA-compliant US data product can coexist in the same mesh under a single governance engine, without manual intervention across jurisdictions.
Data Mesh vs. Data Lake vs. Data Warehouse: 2026
| Dimension | Data Warehouse | Data Lake | Data Mesh |
| Architecture model | Centralized | Centralized | Distributed |
| Ownership | Central IT / BI team | Central data engineering | Business domain teams |
| Governance | Schema-on-write | Schema-on-read | Federated, machine-enforced |
| Scalability | Limited by team capacity | Storage scales; quality doesn’t | Scales with organizational domains |
| Data quality | High for curated priority data | Inconsistent and often poor | SLA-governed per data product |
| Primary use case | Structured BI and SQL reporting | Big data, ML experimentation | Enterprise-scale, multi-domain analytics and AI |
The key differentiation: data mesh is not meant to be a replacement for data lakes or data warehouses. Rather, it’s a governance architecture that could work above the data layer (lakes and warehouses). Most companies implementing a data mesh leave their current data layer (warehouse or lake) in place and build on the mesh concept.
For organizations running business intelligence on top of existing reporting stacks, domain-owned data products significantly improve the quality and reliability of Power BI and SSRS Integration pipelines — reducing ETL complexity and improving dashboard accuracy across business units.
Multi-Source Data Integration in a Data Mesh
Data integration from multiple sources is among the most consistent challenges faced in global enterprise systems – integrating data from SAP, Salesforce, Oracle ERP, legacy systems, cloud-native applications, IoT solutions, local databases, and external API systems into a usable system of operations and analysis.
In centralized models, all integration complexity concentrates on the central data team. In a data mesh, integration is handled at the domain interface layer:
- Each domain exposes data products as event streams (Kafka, Pulsar, Kinesis) or structured APIs (REST, GraphQL)
- Downstream domains subscribe to upstream data products via published data contracts.
- Data contracts define schema, SLA terms, versioning, and ownership — making integration explicit, versioned, and accountable rather than ad hoc and brittle.
The above-mentioned contract-based integration paradigm fits seamlessly into the way enterprise AI solutions are developed. An enterprise AI developer who is tasked with designing an ML pipeline, implementing LLM orchestration, or automating decisions will require a modular, versioned, domain-restricted data feed. The above-mentioned data mesh offers just that.
Data Observability: The Operational Layer That Keeps Mesh Trustworthy
It’s not possible to distribute data ownership across dozens of domain teams without an automated process that continuously monitors whether data products meet their agreed-upon SLAs.
Data observability answers in real time: Is this data product doing what it promises?
Observability platforms in a mesh monitor five dimensions continuously:
| Data Quality Dimension | Key Question |
| Freshness | Is data arriving within its committed time window? |
| Volume Anomalies | Are record counts within statistically expected ranges? |
| Schema Drift | Have upstream systems changed formats without notification? |
| Completeness | Are critical fields being populated at expected rates? |
| Lineage Tracking | Can every analytical output be traced back to its producing domain? |
For enterprises building mesh infrastructure on Azure, Azure migration strategies should incorporate Microsoft Purview as the governance and lineage backbone, providing a unified cataloging and classification, and cross-cloud lineage tracking at the platform level, natively integrated with Azure Databricks, Synapse, and Data Factory.
Implementing Data Mesh: A Phased Enterprise Roadmap
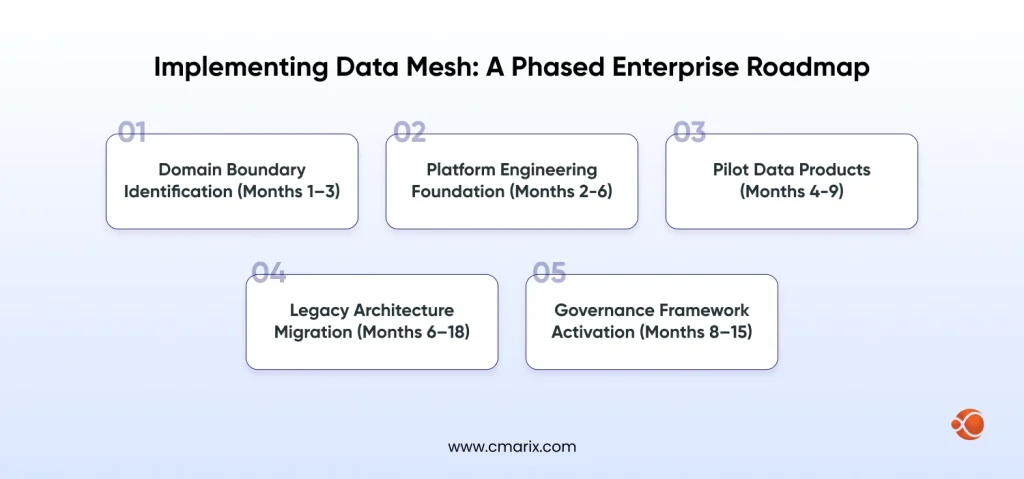
Phase 1: Domain Boundary Identification (Months 1–3)
Map business functions to bounded contexts of domains. A domain is a standalone unit where inputs, processes, and outputs of the system may be defined independent of other domain-based systems. Choose 3–5 key data-driven domains instead of trying to map the entire organization during the first phase.
Phase 2: Platform Engineering Foundation (Months 2–6)
Build the self-serve data platform before any domain goes live. Platform engineering investment is the single strongest predictor of data mesh success. Organizations that underinvest here find that domain teams cannot actually operate independently — recreating the central bottleneck in a different organizational form.
Phase 3: Pilot Data Products (Months 4–9)
Use 2–3 data products within pilot use cases. These early data products establish the benchmark for the quality of data products the organization will produce, help the platform validate itself through use, and provide the evidence needed to drive greater adoption.
Phase 4: Legacy Architecture Migration (Months 6–18)
This is one of the most difficult steps from an operational standpoint. The database migration process is clearly defined and occurs on a domain-by-domain basis, where the highest value and lowest disruption are achieved, while the legacy application continues to run alongside each domain.
The build-vs-buy decision carries significant weight at this stage. A careful analysis of the trade-offs between custom software development and SaaS consistently shows that enterprises with proprietary workflows in regulated industries derive higher long-term value from custom-built mesh infrastructure — while standard-use-case organizations may achieve faster time-to-value from platforms like Databricks Unity Catalog, Collibra, or Atlan.
Phase 5: Governance Framework Activation (Months 8–15)
Governing design policies while building the platform, yet doing so incrementally. Implementing all policies upfront introduces friction within the organization, hindering adoption of the domain. Gradually implement the policies as follows: quality gateways and access controls; data classification and cross-border privacy; and finally, lineage and auditing.
The Business Case: How Data and AI Transform Enterprises at the Architecture Level
Data mesh is not a cost-reduction initiative. It is a capability expansion — one that compounds in value as more domains publish data products and the enterprise’s analytical and AI surface area grows.
When organizations ensure that data and AI transform businesses at the foundational architecture level — not just at the application layer — the downstream effects span every function:
- Reduction in time to insight by 30-50% in initial deployments since domain teams no longer need to queue up in central engineering systems.
- The reliability of the AI system is dramatically enhanced by versioned, SLA-compliant data products that deliver the data quality required by ML models.
- Regulatory compliance becomes operationally tractable as machine-enforced governance replaces manual audit processes across jurisdictions.
- The organization’s agility improves, as use cases scoped to the same domain can be delivered in weeks rather than months.
- Engineering leverage grows as a smaller platform team supports far more active data producers than any centralized model could sustain
For global enterprises navigating AI-era competition, data mesh architecture is increasingly a prerequisite for enterprise-scale analytical capability, not an optional infrastructure upgrade.
How CMARIX Helps Global Enterprises Implement Data Mesh
CMARIX operates a dedicated enterprise data engineering practice built for organizations transitioning from fragmented, centralized architectures to production-grade data mesh environments. Our deployments span industries such as banking, healthcare, logistics, and manufacturing, and take a practical approach rather than a theoretical one.
Our data mesh services cover the full implementation lifecycle:
- Architecture & Strategy: Domain boundary mapping, architectural design for platforms, development of governance models, and technology choices within the AWS, Azure, and GCP clouds.
- Platform Engineering: A self-service data platform which, by its very nature, will be compatible with the current corporate architecture, identity management solution, and governance framework.
- Data Product Development: Working with the relevant domain teams to develop schema agreements, develop pipeline templates, and release production-ready data products with SLAs included.
- Legacy Migration: Structured database migration from central data warehouses/monoliths, organized in a way that reduces disruption and gradually expands the mesh into each new domain area.
For organizations building or modernizing enterprise data infrastructure, hire data engineers from CMARIX who specialize in distributed data systems, cloud-native platform engineering, and data mesh architecture across its full implementation scope.
Enterprise AI developers will build and integrate AI pipelines, such as language model orchestration, retrieval-augmented generation models, vector databases, and inference services for real-time operations, powered by the data mesh as the underlying data platform.
Need cloud-native infrastructure for your mesh deployment? Hire certified AWS developers team from CMARIX to get access to certified engineers ready to architect and optimize AWS-native mesh environments using Glue, Lake Formation, MSK, and SageMaker Feature Store.

Conclusion: The Architecture That Makes Enterprise Data Trustworthy at Scale
Data silos are not a people problem or a tooling problem. They are an architectural problem — and they require an architectural solution.
A data mesh architecture provides global companies with something that has never been provided by any central architecture – decentralized ownership, accountability, and governance without bottlenecks. As the world moves towards 2026 and the era when AI-driven competition, real-time decision-making, and cross-border regulations become the norm, companies that act now are laying the groundwork for future competitive advantage in data architecture.
Whether you are beginning your evaluation or ready to start implementation, CMARIX brings the engineering depth and enterprise experience to guide your organization from fragmented data architecture to production-grade data mesh — domain by domain, with the rigor and governance your global operations demand.
Hire data engineers from CMARIX with the expertise to execute data mesh at full enterprise scale, from domain mapping and platform engineering to governance design and legacy migration — and build the data infrastructure your organization is ready for.
FAQs About Data Mesh Architecture
What is a data mesh, and how does it solve data silos?
The data mesh addresses the issue of data silos by shifting ownership of data away from centralized organizations to the domain organizations that create it. In the data mesh architecture, instead of collecting all enterprise data centrally, domains are in charge of their individual data products, which follow common platform-level standards yet operate autonomously. By doing this, the problem of silos due to organizational misalignment is addressed since those responsible for creating the data are also responsible for making it useful and trusted.
How does Data Mesh differ from Data Lakes and Data Warehouses?
Data warehouses provide structured, centrally curated storage optimized for SQL-based BI and reporting. Data lakes provide flexible, large-scale storage for raw and semi-structured data. Data mesh is neither a storage technology nor a storage format — it is an organizational and governance architecture. It can run on top of a data lake, a warehouse, or both as its storage substrate. The defining difference is ownership: lake and warehouse models rely on central teams to manage all data; mesh distributes ownership to domain teams, with the platform enforcing quality and governance automatically rather than through manual processes.
What are the core pillars of a data mesh?
The four key pillars are: (1) Domain-Based Decentralization – data ownership determined by the domain where the data is produced; (2) Data as a Product – data sets treated as first-class citizens with SLAs, versioning, and ownership defined; (3) Data Infrastructure for Domain Teams as a Platform – a set of common tools that empower domains to build data products independently of central engineering; and (4) Global Policies with Federated Enforcement – global policies enforced by the machines but domain-level autonomy remains.
What are the biggest challenges in implementing a data mesh?
The major concerns are: definition of boundaries of the domain (easier said than done, and particularly difficult in organizations which have been accumulating architectural debt over decades), platform engineering effort (consistently under-estimated; the self-serve platform is the structural support system in the entire ecosystem), organizational change management (the domain teams require different capabilities and culture before being able to take responsibility for owning data), sequencing of migration from the legacy systems (difficult enough that it requires special effort), and governance structure (policies need to be workable in an operational manner without introducing new bottlenecks).
In the case of organizations operating within regulated sectors, the capability to build custom security software development as part of the governance mesh infrastructure is always what makes the difference in terms of whether or not their systems get approved by regulators.
Where can I find examples and resources to get started?
Zhamak Dehghani’s original principles, available at martinfowler.com, remain the definitive foundational reference for understanding the conceptual underpinning of data mesh. The Data Mesh Learning Community provides practitioner case studies, implementation templates, and active peer discussion across industries. For organizations ready to move from research to implementation, CMARIX offers architectural scoping consultations to assess your current data environment, define domain boundaries, and build a sequenced implementation roadmap tailored to your enterprise context and technology stack.




