

Quick Summary: Choosing between RAG and fine-tuning isn’t just a technical call—it defines your AI system’s cost, scalability, and ability to evolve. This guide breaks down both approaches with practical clarity and real-world context, helping you avoid expensive rebuilds and make an architecture decision that holds up not just in pilots, but in full-scale production environments.
Every enterprise AI project eventually hits the same wall. You’ve got a model, you’ve got data, and now someone in the room is asking whether you should fine-tune the model or build a retrieval system around it. Both sound reasonable. Both have real advocates. And picking the wrong one can quietly drain your budget for the next two years.
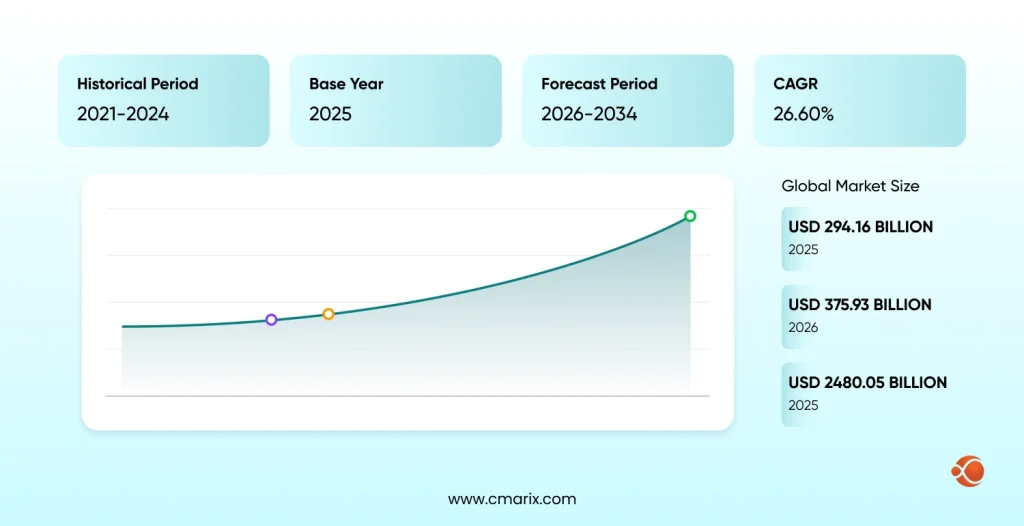
The stakes are real. According to McKinsey’s state of AI report, less than 30% of enterprise AI pilots actually scale to full deployment, and a significant reason is architecture decisions made too early, on too little information. The enterprise AI market reflects this urgency: it’s already valued at $294.16 billion in 2025 and projected to reach $2480.05 billion by 2034. Organizations that get the architecture right early are the ones that scale. The rest rebuild, expensively, under production pressure.
This guide walks through both approaches with enough technical depth to make an informed call, and enough plain language that you don’t need an ML PhD to follow along.
What Is Retrieval-Augmented Generation (RAG)?
RAG is an AI architecture where the model doesn’t rely solely on what it learned during training. Instead, it searches an external knowledge source at query time, retrieves the most relevant content, and uses that content to generate its answer.
Think of it as giving the model access to a library it can search before it responds, rather than expecting it to have memorized every book.
How a RAG Pipeline Works
A retrieval-augmented generation (RAG) pipeline works in a straightforward sequence.
A user submits a query. The system converts it into a vector embedding, searches a vector database for semantically similar content, injects the top results into the model’s context window, and the model generates a grounded response.
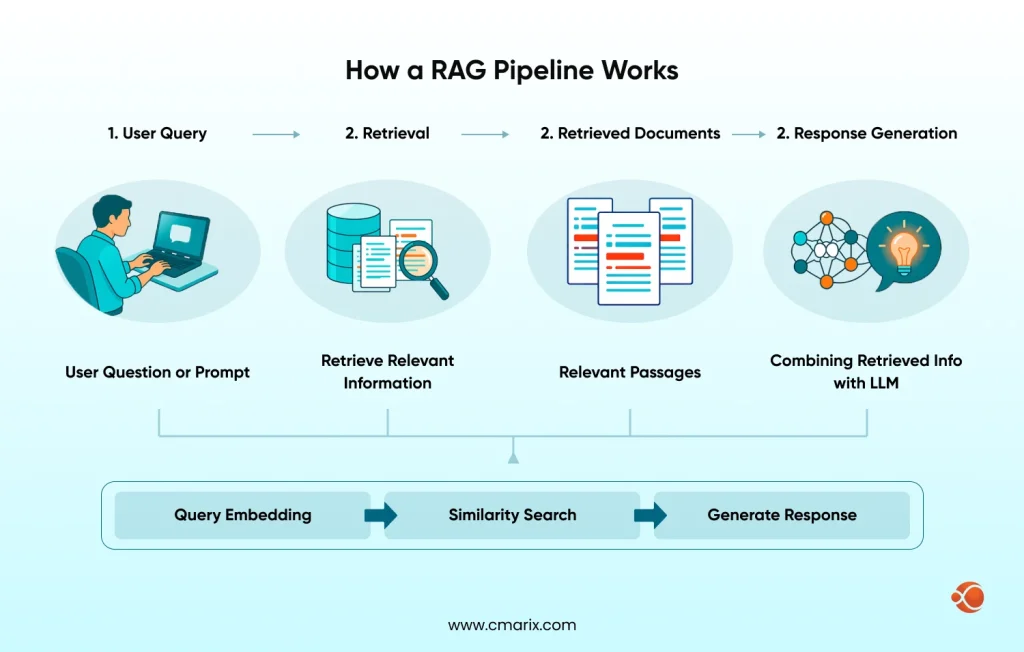
The knowledge lives outside the model, like in documents, databases, internal wikis, PDFs, APIs, and gets pulled in dynamically at inference time. This is the core difference in parametric vs. non-parametric memory:
- Parametric memory — knowledge baked into model weights during training, static and fixed.
- Non-parametric memory — knowledge fetched at runtime from external stores, always current.
Understanding this distinction is the foundation of the entire RAG vs fine-tuning debate.
Key Components of a RAG Pipeline
A production RAG system runs on four components working together:
- An embedding model that converts text into vectors so the system can measure semantic similarity between the query and stored content.
- A vector database (Pinecone, Weaviate, pgvector, Qdrant) that stores and indexes those vectors for fast similarity search.
- A retriever that ranks and selects the most relevant data pieces from the database based on the query vector.
A generator of the LLM itself, that takes the retrieved chunks plus the original query and produces the final response.
Expert tip: The retriever is the most underinvested component in most RAG builds. A better retriever will improve output quality more than switching to a more powerful LLM.
Context window optimization is where most teams underestimate the work. Stuff too many retrieved chunks into the context, and the response quality drops. Retrieve too few, and you miss the answer. Getting chunking strategy, re-ranking, and hybrid search right takes real engineering effort — it’s not a one-time configuration.
Where RAG Fits in the Enterprise AI Stack
RAG works naturally alongside existing enterprise AI consulting engagements because it doesn’t require retraining a base model. You connect the retrieval layer to your existing knowledge systems and deploy. It’s additive rather than disruptive to what you’ve already built.
What Is Fine-Tuning in AI Models?
Fine-tuning takes a pre-trained model like GPT-4, Llama 3, or Mistral, etc., and continues training it on a curated, domain-specific dataset. The goal is to modify the model’s weights so it behaves differently: adopts a specific tone, reasons in a particular way, understands domain vocabulary, or produces outputs in a required format.
What Actually Changes Inside the Model
During fine-tuning, gradient updates adjust the model’s internal parameters based on your training examples. The model shifts away from some general patterns and toward domain-specific ones. This is why domain-specific LLM fine-tuning can produce outputs that feel genuinely native to an industry, because the model has internalized the patterns, not just retrieved them.
This internalization of domain patterns is what separates a well-tuned model from a generic one slapped onto a new use case. It’s also why custom machine learning solutions that include proper dataset curation and training pipeline design produce meaningfully better results than teams that treat fine-tuning as a one-step process.
Full Fine-Tuning vs. Parameter-Efficient Methods
| Points | Full Fine-Tuning | Parameter-Efficient (LoRA, QLoRA, Adapters) |
| Parameters updated | Most or all model weights | Small subset or lightweight adapter modules only |
| Compute cost | High — gradient updates across billions of weights | Significantly lower fraction of full fine-tuning cost |
| GPU requirement | Substantial — long training runs | Manageable for most enterprise teams |
| Output quality | Highest possible ceiling | Approaches full fine-tuning quality in most cases |
| Best for | Maximum domain adaptation, no cost constraints | Practical enterprise deployments with budget realism |
Research from Hugging Face and Stanford NLP has shown parameter-efficient methods approach full fine-tuning quality at a fraction of the compute cost, making them the practical default for most enterprise teams building scalable generative AI solutions.
When Fine-Tuning Is the Right Foundation and When It Isn’t
- Fine-tuning earns its place when your use case demands stable domain behavior: consistent legal reasoning, clinical note generation in a specific format, and financial analysis using industry-specific terminology. It doesn’t earn its place when your data changes frequently, when you can’t afford retraining cycles, or when you need source attribution for compliance.
- One risk worth flagging early is catastrophic forgetting: When you retrain a model on a narrow domain of data, it can degrade on tasks outside that domain. Teams that skip broad evaluation before deployment often discover this problem in production, not in testing.
RAG vs Fine-Tuning for Enterprise: Head-to-Head Technical Comparison
Here’s the honest comparison on the factors that actually matter in production.
| Points | RAG | Fine-Tuning |
| Data freshness | Always current — update the knowledge base without touching the model | Frozen at training time — requires a full retraining cycle to update |
| Adaptability | Continuously adaptable — swap documents, change behavior immediately | Static after training — predictable and consistent, but locked in |
| Hallucination risk | Fails when the retrieval is wrong or returns nothing relevant | Fails when the model extrapolates beyond its training distribution |
| Latency | Higher — retrieval adds 100–300ms round-trip overhead | Lower — single forward pass, no retrieval step |
| Source attribution | Native — can cite exactly which documents drove the answer | Not native — model output isn’t traceable to specific training examples |
| Domain tone and vocabulary | Limited — general model behavior carries through | Strong — domain style and reasoning get baked into weights |
| Infrastructure complexity | Higher — vector database, embedding model, retriever, all required | Lower at inference — complexity sits in the training pipeline |
| Best for | Dynamic data, enterprise search, knowledge management | Stable domains, legal AI, clinical documentation, and financial intelligence |
Wrong choices here don't surface immediately; they show up as expensive rebuilds 12 months into production.
Book a CallData Dependency and Freshness
RAG wins decisively here. Your knowledge base updates without touching the model. For businesses where information changes weekly or monthly, such as regulatory updates, internal policies, product catalogs, and market data, RAG is the only architecture that stays current without a retraining pipeline.
Fine-tuned models are static artifacts. Every essential knowledge update requires a new training run, evaluation cycle, and deployment. For rapidly changing domains, this becomes operationally unsustainable within 12 months.
Model Adaptability Over Time
RAG adapts continuously. Swap the documents, update the vector store, and the model’s effective knowledge changes immediately. Fine-tuning locks knowledge at a point in time. Which is actually an advantage in stable domains where predictable, consistent behavior matters more than freshness.
Performance, Accuracy, and Hallucination Risk
Both approaches have hallucination risks, but for structurally different reasons. RAG hallucinates on retrieval failure: on the wrong chunk retrieved, on ambiguous queries, or on a lack of relevant information in the store, and the model fills in the gap.
Fine-tuned models hallucinate on out-of-distribution extrapolation. An AI model fine-tuned on contract law will confidently answer incorrectly on tax law.
The mitigation strategies are completely different for each, which is why treating hallucination as a single problem with a single fix is a common and costly mistake.
Latency: What the Benchmarks Actually Show
Fine-tuning excels in the area of latency. A fine-tuned model responds in real time; one forward pass, and we’re done. RAG has a second path to take. Embed the query, search the vector database, retrieve the pieces of information, and then inject them. While the latency in the vector database isn’t terrible, the vector database latency itself is manageable, but the full RAG process will take 100-300ms.
The Business Decision Lens: What Enterprises Actually Care About
Technical performance is necessary but not sufficient. Here’s what actually moves the needle at the budget and governance level.
Total Cost of Ownership
The cost of fine-tuning is high, especially in the beginning, which includes the cost of data curation, computation, labeling, evaluation, and the actual cost of the multiple rounds of retraining. This cost can run into tens of thousands of dollars for a single run on large models, especially for GPUs. Parameter-efficient approaches bring this cost down substantially, but the cost of maintenance of the infrastructure for retraining will still remain.
The cost of RAG is much less, but there will always be the cost of infrastructure. Therefore, in a 12-36 month period, the choice between the two will heavily depend on the rate at which your data is changing. In fact, the U.S. federal government has set aside $168M-$224M for AI infrastructure and deployment support, which goes to show even for those with deep pockets, infrastructure cost is a key variable in the cost-benefit equation for AI, not a minor footnote.
Compliance, Data Privacy, and Security Posture
For GDPR, HIPAA, or SOC 2 environments, where your data lives matters as much as what the model produces. RAG systems that retrieve from third-party vector stores or external APIs, which can create data residency complications that a self-hosted fine-tuned model avoids entirely. Secure enterprise applications need compliance decisions made at the architecture stage; retrofitting security posture after deployment is far more expensive.
Infrastructure Requirements and Vendor Lock-In
Fine-tuned models are generally portable — host them on AWS, Azure, GCP, or on-premises. Some RAG pipelines create hard dependencies on specific vector database vendors or embedding API providers that are costly to undo later. Evaluating enterprise application integration best practices before committing to a stack can prevent years of vendor friction.
Maintenance Burden and Scalability Over 12–36 Months
RAG systems require continuous retrieval quality monitoring: document freshness, query drift, and chunk relevance. Fine-tuned models require retraining schedules, dataset maintenance, and evaluation pipelines. Neither is maintenance-free; the real question is which maintenance burden maps better onto your team’s existing capabilities and roadmap.

When RAG Is the Right Choice for Enterprise
RAG is the right foundation when:
- Your data changes frequently like weekly, daily, or in real time, and retraining on every update isn’t operationally viable.
- Source attribution is a compliance requirement, and you need the model to cite which documents drove its answer.
- You need to reach production quickly without standing up a full training pipeline.
- Access controls need to operate at the document level, not at the model level.
- You’re building enterprise search, customer support, or knowledge management systems where the underlying content is always evolving.
That said, retrieval quality is everything and hard to get right. Bad chunking strategy, poor metadata filtering, or weak embedding models cause retrieval to fail silently — and the model hallucinates to fill the gap. Teams looking for generative AI integration services often underestimate this part — the retrieval layer is not a solved problem you configure once and forget.
When Fine-Tuning Is the Right Choice for Enterprise
Fine-tuning earns its place when domain behavior needs to be consistent, native, and not dependent on what the retrieval layer surfaces. Clinical documentation, legal AI, and financial intelligence are the canonical examples.
These domains have stable knowledge structures, required output formats, specific vocabulary, and reasoning patterns that a general model handles poorly without training. Expert AI Fine-tuning services make the most sense when the use case demands reasoning within a domain framework — not just retrieving from domain documents.
A RAG system can retrieve the right information and still generate it in a way that feels generic. Tone, structure, domain vocabulary, and reasoning style are things the model has to embody — and that requires training, not retrieval. If you need to train an LLM on domain-specific data, the dataset quality and curriculum design matter as much as the training method itself.
The real limitations to plan around:
- Knowledge is frozen at training time — any update requires a new training cycle
- Retraining is expensive and time-consuming, especially at scale
- Catastrophic forgetting risk is real if the training domain is too narrow
- Output isn’t traceable to specific training examples, which complicates auditing
Real-World Enterprise Deployments: What the Evidence Shows
Theory is useful. What enterprises have actually built is more useful.
Microsoft Copilot: RAG at Enterprise Search Scale
Microsoft’s Copilot is the clearest enterprise-scale RAG deployment in existence. Rather than baking every user’s documents, emails, and calendar into a model’s weights, Copilot retrieves from a user’s specific Microsoft 365 data at query time. The base model stays the same; what changes per user is the retrieved context. This scales to millions of enterprise users because retrieval is personalized — not training.
Harvey AI: Fine-Tuning for Legal Intelligence
Harvey AI was built on fine-tuned models specifically because legal reasoning requires more than retrieving legal documents. The model needs to reason within legal frameworks — analyze precedent, structure arguments, and apply jurisdiction-specific logic. That behavior has to be in the weights. RAG alone doesn’t produce it reliably enough for professional legal use.
Ambiance Healthcare: Clinical Documentation with Fine-Tuned Models
Clinical documentation is a case where output format is non-negotiable: ICD-10 codes, structured SOAP notes, and specific medical terminology. Ambiance Healthcare’s system uses fine-tuned models because the domain’s requirements are both stable and highly structured — exactly the conditions where fine-tuning outperforms retrieval.
OpenAI’s Enterprise Fine-Tuning
OpenAI’s enterprise fine-tuning offering lets companies adapt GPT-4o on proprietary datasets through their API. In practice, enterprise clients use it for customer service tone customization, specialized coding assistants, and domain-specific document generation — not for knowledge that changes frequently. The pattern is consistent: fine-tuning for behavior, RAG for knowledge.
CMARIX’s Hybrid Implementations
Across enterprise clients in logistics, legal, healthcare, and financial services, CMARIX has found that the highest-performing production deployments combine both layers. The dual-layer approach produced measurably better output quality than either architecture alone, a fine-tuned reasoning layer paired with a RAG pipeline for live project data.
The Hybrid Approach: When RAG + Fine-Tuning Work Together
Here’s what most architecture guides skip: the majority of production-grade enterprise AI systems don’t choose one or the other. They use both, and for good reason. A fine-tuned model “knows how to think” about a domain. A RAG pipeline gives it current, accurate information to think about. These are complementary, not competing. A legal AI model fine-tuned on the reasoning of case law, coupled with the RAG pipeline of current regulations, performs better than either architecture alone.
The inference flow of the model would be as follows:
- User query activates the model’s retrieval layer
- Relevant documents are fetched from the vector store
- Documents are fed into the model’s context window along with the user query
- Output from the fine-tuned model would be domain-specific and fact-specific
The fine-tuning layer handles style, format, and domain reasoning. The retrieval layer handles facts, current knowledge, and source attribution. Neither layer has to do the other’s job.
This architecture is particularly powerful when building out an enterprise AI Agents implementation framework where agents need to plan, reason, and act — not just answer questions. Agents operating in complex enterprise workflows need both capabilities simultaneously, and the hybrid architecture is the only way to give them both reliably.
The tradeoff is complexity. Hybrid systems are harder to build, debug, and evaluate. Here’s what that complexity looks like in practice:
- Cost is higher than RAG alone
- Latency is higher than fine-tuning alone
- Evaluation becomes two-dimensional; retrieval quality and model behavior need to be tested independently before being tested together
- Debugging failures requires identifying whether the problem is in retrieval or generation
For high-stakes production use cases, the performance premium justifies it. For simpler use cases, it’s often overkill.
CMARIX’s hybrid AI architecture framework starts with a pre-deployment architecture review and designs the layered architecture from those answers rather than defaulting to a template.
Common Pitfalls and How to Avoid Them
Most enterprise AI failures aren’t caused by bad models. They’re caused by solvable problems that weren’t caught before production.
Catastrophic forgetting in fine-tuned models
A model retrained on narrow domain data can lose general reasoning capability. Teams discover this in production when users ask questions adjacent to the training domain and get confidently wrong answers. The fix is broader evaluation before deployment — test on tasks outside your training distribution, not just inside it.
Retrieval quality failures in RAG pipelines
The model doesn’t know retrieval failed — it fills the gap with plausible-sounding content. The mitigation is treating retrieval evaluation as a separate engineering problem: test retrieval in isolation, monitor retrieval quality in production, and don’t assume that having documents in a vector store means the model will find the right ones.
The fastest way to catch retrieval failures before they reach production is to build a focused proof of concept against real data before committing to the full architecture. AI PoC development that specifically stress-tests the retrieval layer, surfaces these failures at the cheapest possible stage.
Measuring the wrong things
Most enterprise AI evaluations measure fluency, user satisfaction, or task completion rate. These are useful but insufficient. What matters for knowledge-based systems is factual grounding accuracy — whether the output is actually true, not just well-written. Automating DevOps with ChatGPT and similar automation use cases are particularly vulnerable here, because a fluent but factually wrong output in an automated pipeline causes real downstream damage.
Evaluation gaps: why teams measure the wrong things
Building an evaluation harness before you build the system — not after — is one of the highest-leverage things you can do. CMARIX’s pre-deployment architecture review exists precisely to catch these issues at the design stage rather than under production pressure.
Expert tip: Add a factual grounding metric to your evaluation suite from day one — even a simple one. Measuring whether the answer is traceable to a source document catches more production failures early than any fluency score will.
Decision Framework: 5 Questions to Find Your Answer
Use these five questions in order. The first answer that points clearly in one direction will normally dominate the rest.
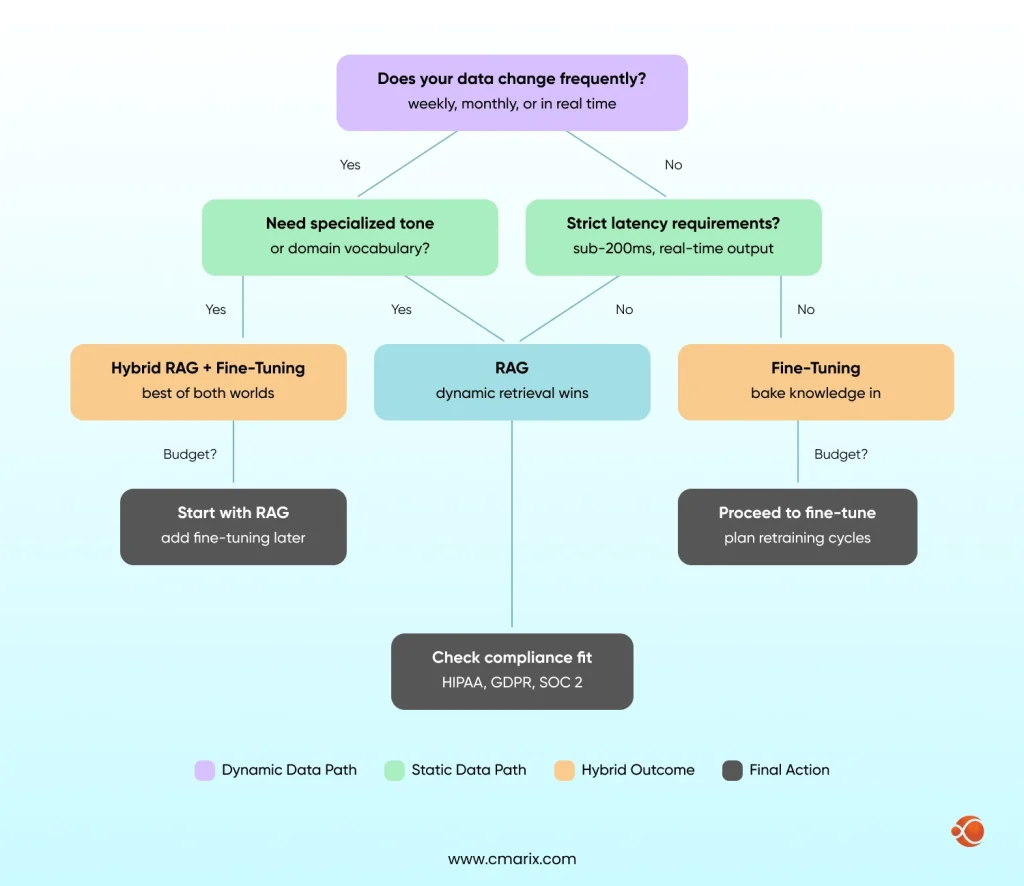
Question 1: How frequently does your data change?
Daily or weekly → RAG is required. Quarterly or less → fine-tuning is viable.
Question 2: Do you need proprietary tone or domain vocabulary?
Yes, consistently → a fine-tuning layer is non-negotiable. No, general language works → RAG may be sufficient on its own.
Question 3: What are your latency constraints?
Sub-200ms hard requirement → fine-tuning. More lenient → RAG’s retrieval overhead is workable.
Question 4: Where are your compliance boundaries?
Strict Data Residency Requirements → Self-Hosted Fine-Tuned Model. Source Attribution Required → RAG. Both → Hybrid with Careful Architecture Design.
Question 5: What is your realistic 12-month AI budget?
Limited → Use RAG as a starting point and add fine-tuning on a selective basis. Ample → design hybrid from Day One. Understanding the ROI of AI/ML outsourcing before making a call on whether to build or outsource to a specialized partner can be worth the time spent.
The flowchart below maps these five questions to architecture outcomes:
Work with CMARIX to Architect, Build, and Deploy Your Enterprise AI System
Architecture decisions made before a build are the cheapest ones you’ll make. Once a team has committed to a RAG pipeline, built retrieval infrastructure, and integrated it into production workflows, changing direction costs months and a significant budget.
CMARIX’s enterprise AI practice covers the full spectrum: building custom AI software, retrieval pipeline engineering, fine-tuning with LoRA and QLoRA, and hybrid architecture design across legal, healthcare, financial services, and logistics verticals. If your team needs to scale the build layer quickly, you can also hire expert backend developers through CMARIX to accelerate delivery without sacrificing architecture quality. The conversation always starts with architecture — not tools — because that’s where the leverage is.
For teams managing the infrastructure layer, AWS DevOps consulting support ensures the deployment environment is production-ready before the model ever goes live. And if you’re currently outsourcing enterprise DevOps specialists to support a growing AI operation, CMARIX can integrate at whatever layer is most useful — architecture, build, or ongoing optimization.
Talk to the CMARIX team before you commit to an approach. That conversation is significantly cheaper than rebuilding after the fact.

Conclusion: Making the Right Call — and the Right Partner
RAG vs fine-tuning for enterprise isn’t a question with a universal answer. It’s a question with a specific answer for your data dynamics, your compliance constraints, your latency requirements, and your 12-month budget reality.
Most teams that get it right start with clear answers to those five questions — not with a preferred technology. Partnering with a team that builds custom enterprise software solutions with AI embedded from the foundation is what separates deployments that scale from those that get rebuilt. The hybrid approach is where the best production systems land, but hybrid systems are more complex to build and require a higher standard of evaluation discipline.
What’s clear is that the architecture decision is the highest-leverage decision you’ll make in an enterprise AI project. Get that right and everything downstream becomes significantly more tractable. Get it wrong, and you’re rebuilding — expensively, under production pressure — while the opportunity window narrows.
Have an Interesting Project? Let’s talk about that.
CMARIX builds production-grade enterprise AI, from architecture review through full deployment, across legal, healthcare, financial services, and logistics.
Inquire NowFAQs on RAG vs Fine-Tuning for Enterprise
What is the key difference between RAG and fine-tuning for enterprises?
RAG retrieves external knowledge at query time from a vector database without modifying the model’s weights. Fine-tuning adjusts the model’s parameters through additional training on domain-specific data. RAG handles dynamic, frequently changing information well. Fine-tuning handles stable domains where consistent tone, vocabulary, and reasoning patterns matter most.
When should an enterprise choose RAG over fine-tuning?
When data changes frequently, when source attribution is required for compliance, when access controls need to operate at the document level, or when you need to reach production quickly. Enterprise search, customer support, and knowledge management are the strongest RAG use cases.
Is fine-tuning better for specialized industries like legal or healthcare?
Yes, for core domain reasoning. Legal AI has to reason within the legal framework, not just retrieve legal documents. Clinical documentation has to have a specific output format and terminology, which the above models don’t provide. Harvey AI and Ambiance Healthcare both demonstrate that fine-tuning is the right foundation when domain behavior needs to be embedded, not retrieved. That said, even these systems typically pair fine-tuning with a retrieval layer for current information.
Which architecture is more cost-effective: RAG or fine-tuning?
This varies based on your time horizon and data change frequency. RAG has a lower upfront cost but a high infrastructure cost. Fine-tuning has a high upfront cost but a low cost per query. For high data change frequency, there are no expensive retraining cycles for RAG. For stable domains and high query volume, fine-tuning may have a lower cost per query.
Can RAG and fine-tuning be used together?
Yes, and most production-quality enterprise AI systems actually do this. The fine-tuned model takes care of domain reasoning, output format, and tone. The RAG pipeline takes care of the most recent and accurate facts and the attribution of the sources. The combination works better than either model in isolation for more complex use cases. The combination is more complicated to implement and evaluate.
How does catastrophic forgetting affect enterprise fine-tuning?
If the model is fine-tuned on the new data within a narrow domain, the model’s performance on other tasks outside the training domain will deteriorate. While full fine-tuning poses the greatest risk, the parameter-efficient methods, such as LoRA, minimize but do not eradicate the risk. The solution to the problem lies in extensive evaluation prior to deployment and in the adoption of LoRA over full fine-tuning unless the application demands it.




