

Quick Overview: Chatbot AI never lies. Instead, it uses probabilities to generate its answers. In the absence of validation procedures such as RAG, validation checks, and output processes, chatbots may generate answers that sound confident but are untrue. This detailed guide on AI chatbot hallucinations explains more about why your AI chatbot is always lying or giving incorrect results.
You created your chatbot. It was supposed to assist customers, speed up internal information retrieval, or facilitate an entire process. And all of a sudden, it started making things up.
Wrong product specs. Fabricated legal citations. Non-existent policy clauses stated with complete authority, and 404 page links that never existed. This phenomenon has a name: AI hallucination.
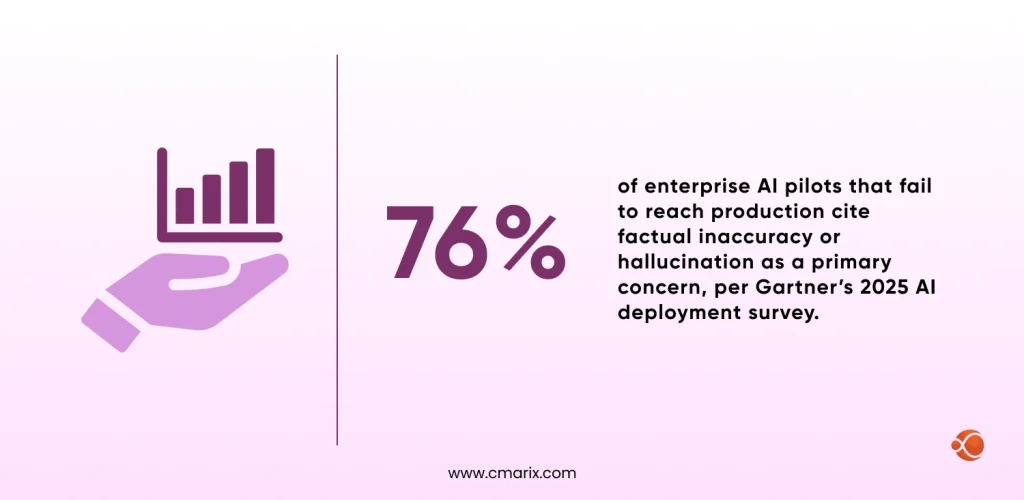
And according to research from Stanford HAI, hallucinations are not edge cases; they are widespread. In legal-specific evaluations, large language models produced incorrect or fabricated answers in 69% to 88% of queries, and at least 75% of the time when identifying core court rulings.
This is not a minor bug. It is a structural consequence of how large language models are built. Fixing it requires understanding the architectural roots of the problem, not just sprinkling “be accurate” into your system prompt.
The problem isn’t model intelligence, it’s the probabilistic nature of language generation: LLMs predict the next word based on patterns in training data, not verified facts, so without grounding mechanisms, they can confidently produce content that sounds plausible but is factually wrong.
What Is an AI “Hallucination”?
A hallucination is an example in which the text produced by the language model contains falsehoods, lacks verifiable sources, and is completely made up, yet with the same level of certainty as truthful text. The language model does not question itself and makes it up as it goes along. According to the International AI Safety Report 2026, such problems include various types of errors and fabrications.
This matters acutely in industries where a wrong answer carries real-world consequences, such as healthcare, legal tech, financial services, and compliance. Understanding the security risks of public AI models, hallucination-prone systems in sensitive contexts is the first step before any architecture decision.
“A language model doesn’t ‘know’ things the way humans do. It learns statistical patterns across tokens. When asked something outside its training distribution, it doesn’t stop, it extrapolates, fluently.”
The ability to talk convincingly, which characterizes contemporary LLMs, is actually one of their most problematic features. Such systems have become very skilled at producing grammatically correct statements, even if those statements are incorrect. Users trust language that sounds right.
The 5 Root Causes Behind AI Chatbot Hallucinations(It’s Not Stupidity)
To fix hallucinations, you have to understand why they happen. There is no single cause; there are five distinct architectural and epistemological failure modes, and most enterprise deployments suffer from at least three simultaneously. Comprehensive analyses, such as this arxiv study on hallucination mechanisms, break them down further into training gaps and inference flaws.
01: Probabilistic Text Generation
The model predicts the most probable next token, not necessarily the correct one. Large Language Model (LLM) Accuracy and coherence are independent goals, and the model aims for the latter.
02: Training Data Cutoff
Models have knowledge about cutoffs. Any question about events, products, or regulations after that date forces the model to extrapolate, thereby dramatically increasing the risk of hallucinations.
03: Context Window Limitations
Having a large window size does not mean that all the facts within it will be used by the LLM; they will most likely be ignored.
04: No Native Uncertainty Modeling
There is no uncertainty modeling function within base LLMs. Models are trained to generate coherent responses to prompts without indicating uncertainty.
05: Instruction-Following Pressure
RLHF fine-tuning trains models to be more complete and helpful. This creates a bias toward giving an answer, any answer, rather than refusing or hedging. Helpfulness and truthfulness often conflict, with helpfulness given priority.
The Compounding Problem in Enterprise Deployments
In a generic consumer chatbot, hallucinations are annoying. In an enterprise system, an AI telemedicine chatbot development, a compliance advisor, and a customer-facing product assistant are catastrophic. The consequences become more serious because the AI model is being used as an authoritative interface to access data it was never trained on. According to a ResearchGate study on AI hallucinations, these AI hallucinations affect people in multiple ways and stress the urgency of setting up layers of defense to avoid them.
And this is the core issue: developers see the LLM as a source of knowledge, while, essentially, it is an instrument for completing patterns. It was trained on the Internet. Your unique SOPs, your up-to-date drug formularies, your real-time inventory, none of that was on the web.
AI Chatbot Architecture Fixes That Actually Work
Prompt engineering alone will not solve hallucination. Real fixes require structural changes at the system design level.
Fix 1: Retrieval-Augmented Generation (RAG)
RAG is currently the most robust production-grade solution for reducing hallucination in domain-specific deployments. Instead of asking the model to recall facts from its weights, you retrieve relevant documents at inference time and inject them as grounding material.
RAG Pipeline Flow:
User Query → Embedding Model → Vector DB Lookup → Top-K Chunks → LLM + Grounded Context → Cited Response
A good RAG system must not only retrieve documents but also include citations, confidence intervals, and fallbacks if the retrieval process is not up to standard. When designing a pipeline for RAG, it is important to understand the differences between vector databases and traditional databases in AI applications.
Fix 2: Confidence Thresholds and Refusal Policies
Any production AI system should have explicit “I don’t know” architecture:
- Minimum retrieval relevance scores before injecting context (e.g., cosine similarity ≥ 0.82)
- Classifier layers that detect out-of-domain queries before they reach the LLM
- Explicit fallback responses when confidence is below the threshold* Fallback messages when confidence falls below the level set
- Post-generation fact-checking using a second validation model or structured data parsing
Fix 3: Structured Output Enforcement
The process of hallucination occurs easily if responses are given in their natural language form. Using a structured response format, such as a JSON schema, keeps the space for generation minimal. When an AI is expected to respond based on data collected from various sources, there is no scope for anything else.
Fix 4: Self-Hosted Architecture
For those who have stringent requirements around data governance, the choice in architectural approach from the standpoint of self-hosted AI architecture vs OpenAI APIs is no longer simply a financial matter; rather, it is one of reliability and control. For those considering this option, they should look into deploying private LLMs on AWS.
Fix 5: Guardrail Layers
The most appropriate architecture should contain: RAG to provide context to the response based on the source document; thresholds for the confidence interval and contingency planning; formatting of the response to limit the output; classifiers to manage input/output; citations for the information sources used in the model; and human monitoring to generate responses with low confidence intervals.
Is Your AI Architecture Hallucination-Proof?
CMARIX specializes in building enterprise-grade AI systems with grounding, RAG pipelines, and guardrail layers that eliminate uncontrolled hallucination risk.
RAG vs Fine-Tuning: Choosing Your Weapon For More Honest AI Chatbots
Practitioners often ask: Should we retrieve or should we train? The honest answer is that these approaches solve different problems, and the best enterprise systems use both.
| Dimension | RAG | Fine-Tuning |
| Knowledge freshness | ✅ Real-time, always current | ❌ Requires retraining for updates |
| Factual grounding | ✅ Source-attributable citations | ⚠️ Embedded in weights, harder to audit |
| Domain tone/style | ⚠️ Depends on base model | ✅ Highly customizable |
| Hallucination risk | ✅ Low with quality retrieval | ⚠️ Can amplify if training data has errors |
| Infrastructure cost | ⚠️ Vector DB + retrieval layer | ❌ GPU-intensive training runs |
A detailed treatment is in our guide to RAG vs Fine-Tuning: choosing the right AI architecture for enterprise applications. The short version: use RAG for factual accuracy and knowledge recency; use fine-tuning for behavioral alignment and task-specific reasoning. For high-stakes domains, layer them.
Regulatory Context: The EU AI Act and Hallucination Accountability
It is no longer just about technology. To ensure compliance with the EU AI Act, AI systems in the high-risk category must be designed to be explainable, auditable, and controllable. The rise of systems that allow every output to be traceable to a retrievable source and that come with confidence scores becomes prevalent.
Enterprise AI Chatbot Auditing/Deployment Checklist
If you’re building or auditing an AI chatbot deployment, run through these checkpoints before going to production. CMARIX uses this framework across its generative AI development services engagements.
| Check | Implementation | Risk Reduction |
| RAG pipeline active | Vector DB + retrieval at inference | High |
| Retrieval confidence threshold | Minimum cosine similarity score set | High |
| Refusal policy defined | Out-of-domain queries return structured fallback | Medium-High |
| Output schema enforcement | JSON / structured format for critical responses | Medium |
| Citation attribution enabled | Response includes source document reference | High |
| Guardrail classifier layers | Input + output validators deployed | Medium-High |
| Human-in-the-loop | Low-confidence outputs flagged for review | High |
| Monitoring & drift detection | Hallucination rate tracked in production | Medium |
| Private deployment evaluated | VPC-isolated inference for sensitive data | Medium |
| Fine-tuning on domain data | Task-specific behavioral alignment | Medium |
Each checklist item represents a dedicated engineering workstream. Our team of dedicated AI engineers and data engineering expert handles the full stack, from vector database configuration to guardrail layer deployment.
Starting From Scratch? Validate Before You Build
The best cost-saving starting point is by validating concepts via an AI Proof of Concept. This targeted proof-of-concept phase allows you to test retrieval effectiveness, assess hallucination rates in your domain, and identify gaps in the architecture.
Mobile AI and Voice: The Emerging Frontiers
The possibility of hallucination isn’t nullified by the mobile layer either. The privacy-first mobile AI apps face a problem: on-device inference protects user data but often lacks a grounding in real-world context. Likewise, there is a risk of hallucinations in the generation layer that creates text for TTS in the context of business communication. Hallucinations in speech are even worse than on paper.
Final Words
AI chatbots don’t lie because they are malicious. They lie because they are probabilistic systems tasked with performing deterministic tasks without the architectural scaffolding needed to enforce factual accuracy. The gap between what users expect and what base LLMs deliver is not a problem of model intelligence; it is a system design problem.
The good news is that the engineering solutions exist. At CMARIX, we have helped organizations across healthcare, fintech, legal, and manufacturing move from hallucination-prone pilots to enterprise-grade AI systems with measurable accuracy improvements. Whether you’re starting with a PoC, rebuilding a fragile deployment, or architecting from scratch, our team brings the full-stack AI engineering depth to solve this properly.
FAQs about AI Chatbot Hallucinations
What is an AI “hallucination”?
In terms of AI hallucinations, it involves large language models creating factual errors or made-up information in an ordinary tone when generating text. In essence, there is no inherent way to express uncertainty about the texts generated by language models, and thus, the output text will be based solely on statistical accuracy.
Why does ChatGPT lie instead of saying “I don’t know”?
The model rewards helping behavior and task completion. This implies a hidden bias towards giving a response rather than declining to do so. If the model lacks credible information, it doesn’t stall; it infers the pattern from the distribution of the training data.
What are the main architectural causes of AI chatbots lying?
The primary reasons for this from the perspective of architecture are: (i) Probabilistic text generation with a focus on fluency over truthfulness; (ii) Cut-off points in training datasets; (iii) Context window length and degradation of attention mechanisms; (iv) Lack of native uncertainty estimation in the base LLM architecture; and (v) Instruction-completion bias in RLHF training.
How can we fix AI chatbot hallucinations using architecture improvements?
The best architectural methods would be: RAG for grounding the answer in the source document; thresholds for confidence levels and fallback strategies; structural formatting of the answer to limit the output; classifiers for input and output controls; citations for sourcing facts used by the model; and human oversight for generating answers with lower confidence levels.
How can I get more accurate results from ChatGPT?
For personal use: provide the model with clear context, tell it to reference sources, and encourage it to respond “I don’t know” when unsure. If you are deploying your own enterprise solution, the only way to achieve consistent, predictable accuracy is through the architectural solutions listed above. Prompting techniques help, but cannot eliminate hallucinations completely.




