

Quick Summary: Choosing between vector databases and traditional databases is a critical decision for modern AI applications. While relational databases excel at structured, transactional data, they fall short at handling unstructured content such as text and images. Vector databases enable semantic search and support use cases such as RAGs and recommendation systems. This guide helps enterprises decide when to use each and why a hybrid approach often delivers the best results.
The database powering your CRM was never designed to understand language. It was built to find rows, not meaning, and that distinction is now costing enterprises millions in missed AI potential.
As organizations build AI-powered applications , from intelligent search engines to recommendation systems and Retrieval-Augmented Generation (RAG) pipelines, a quiet infrastructure battle is being fought beneath the surface. On one side: the battle-hardened relational databases that have served enterprise IT for decades. On the other hand, a new class of purpose-built data infrastructure engineered for the way large language models actually think.
This guide breaks down the core differences, the technical trade-offs, and how organizations are making smarter decisions about their AI data infrastructure, including the critical choice between self-hosted AI deployments vs OpenAI APIs, as well as the broader infrastructure decisions that follow.
The Problem With Traditional Databases in AI Workflows
Traditional relational databases such as PostgreSQL, MySQL, and Microsoft SQL Server are extraordinarily good at what they were designed for: storing structured data in tables, enforcing schema constraints, and executing precise queries using indexed scalar values.
A typical query looks like this:
- “Find all clients who have an account balance of more than $10,000 and have logged in in the last 30 days.”
- This would be a scalar search, meaning the database evaluates numerical thresholds to find exact matches.
Where Traditional Databases Break Down for AI
Language, images, and user behavior do not map cleanly to scalar values. When a user types “affordable running shoes for flat feet,” a traditional database has no conceptual way to match that phrase against product descriptions unless every possible variation has been indexed in advance. There is no column called “semantic intent.” The data model was never designed for meaning.
This fundamental limitation becomes a critical bottleneck when organizations are:
- Integrating AI into legacy systems using .NET Core
- Migrating enterprise workflows toward AI-native architectures
- Building LLM-powered assistants on top of proprietary document libraries
- Running a semantic search across unstructured product catalogs or support histories
What Is a Vector Database?
A vector database is a purpose-built data store that indexes and retrieves high-dimensional embeddings, numerical representations of unstructured data such as text, images, audio, or code, using mathematical similarity rather than exact matching.
How the Pipeline Works
- Raw unstructured data (a product description, a support ticket, a document) is passed through an embedding model.
- The model converts that data into a vector, a list of floating-point numbers representing semantic meaning in a high-dimensional space (typically 768 to 4,096 dimensions).
- These vectors are stored and indexed in the vector database.
- At query time, the user’s input is also converted to a vector, and the database retrieves the items whose vectors are closest in that dimensional space, a process called similarity search algorithms.
The result: a database that can find meaning, not just matching characters. This underpins virtually every modern AI use case from
This capability underpins virtually every modern AI use case, from AI recommendation systems for mid-market businesses to semantic document retrieval and conversational AI.
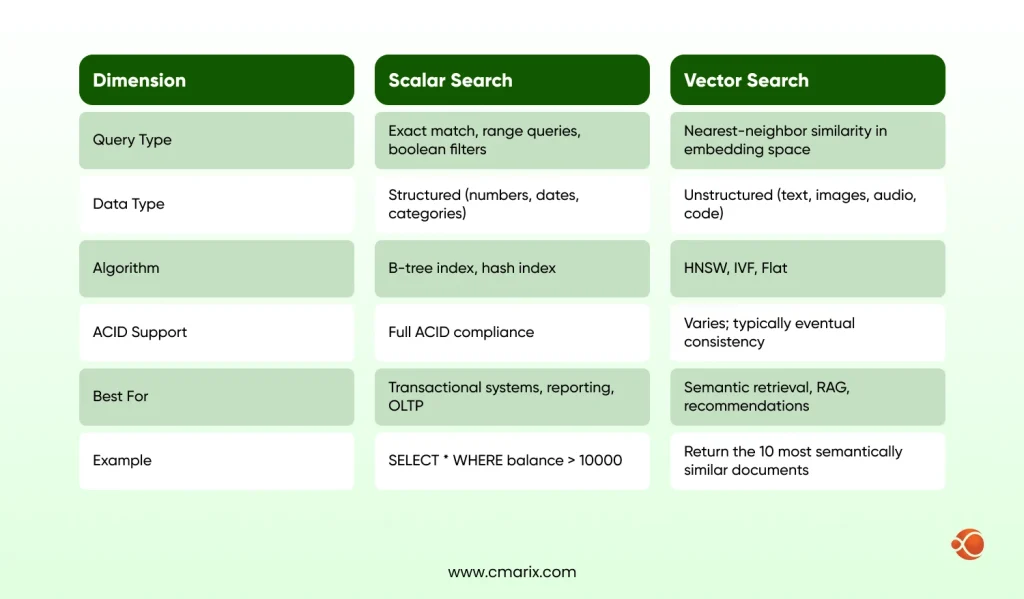
Scalar Search vs. Vector Search: A Technical Breakdown
Understanding the difference between these two paradigms is critical before making any infrastructure decision.
Key Vector Indexing Algorithms
The two most common indexing approaches in production vector databases:
- HNSW (Hierarchical Navigable Small World): A graph-based index that creates layered navigable networks for fast approximate nearest neighbor (ANN) search. Excellent for high-throughput, real-time applications.
- IVF (Inverted File Index): A clustering-based approach that partitions vectors into groups and searches only the most relevant clusters. More memory-efficient at massive scale (100M+ vectors).
Neither indexing mechanism has a corresponding SQL approach. Developers working on high-dimensional embedding pipeline implementations or Retrieval-Augmented Generation models always face the same problem.
Build smarter AI systems with the right data foundation
Can Traditional Databases Handle Vector Data?
One of the most common questions from engineering teams is: “Can traditional databases like PostgreSQL handle vector data?”
The short answer: yes, with significant caveats.
The pgvector Extension: Capabilities and Limits
Pgvector for PostgreSQL is an extension that enables organizations to embed vector embeddings in their relational databases. It can be used by businesses whose work requires fewer than a million vectors, provided there is no need for excessive queries per second.
However, pgvector has known limitations at scale:
- The time to build an index grows too long beyond about 10 million vectors.
- The quality of ANN recall is not guaranteed without careful parameter tuning.
- Query performance on a heavy load was outperformed by specialized vector indexing solutions.
- No native GPU-accelerated vector indexing, which becomes critical for sub-100ms response times at enterprise scale
| Factor | pgvector (PostgreSQL) | Dedicated Vector DB (e.g. Pinecone, Qdrant) |
| Setup Complexity | Low, extends existing infrastructure | Moderate, requires a new service to operate or manage |
| Scale Ceiling | ~10M vectors comfortably | Billions of vectors |
| Query Latency | Acceptable at low scale | Sub-10ms at high throughput |
| GPU Indexing | Not supported | Supported (e.g., Milvus, Qdrant) |
| ACID Compliance | Full (inherits PostgreSQL) | Partial or eventual consistency |
| Best Use Case | Early-stage, hybrid, low-scale applications | Production AI at enterprise throughput |
For production-grade generative AI integration services at enterprise throughput, a dedicated vector database is typically the right long-term architecture.
Why Vector Databases Are Preferred for LLMs and Generative AI
This is perhaps the most commercially significant question in enterprise AI infrastructure today.
LLMs like GPT-4 or Claude are trained on massive datasets, but their knowledge is frozen at training time. They cannot know what happened last week, what your proprietary product catalog contains, or what your internal compliance documents say, unless that information is fed to them at inference time.
Retrieval-Augmented Generation (RAG): The Core Use Case
Rather than fine-tuning a model on every piece of proprietary data (expensive, slow, and frequently over-engineered), RAG retrieves the most contextually relevant documents at query time and injects them into the model context window.
How a RAG pipeline works in practice:
- The user submits a query.
- The query is converted to a vector embedding using the same embedding model as your document index.
- The vector database retrieves the top-k most semantically similar document chunks.
- Those chunks are passed to the LLM as context alongside the original query.
- The LLM generates a grounded, accurate response based on your proprietary data.
For teams evaluating LLM fine-tuning data best practices against RAG systems for their applications, the emerging trend in the machine learning community is clear: RAG, with efficient vector search, is more cost-effective and maintainable than fine-tuning in most cases.
CMARIX has helped enterprise clients design and deploy vector-backed RAG pipelines that dramatically reduce hallucination rates while keeping retrieval latency under 200ms, a threshold that matters for real-time conversational interfaces with our AI model fine-tuning and LLM development services.
Unstructured Data Management: The Hidden Bottleneck
IBM research estimates that 80-90% of enterprise data is unstructured, including emails, PDFs, support tickets, product images, call transcripts, and engineering documentation.
This data is currently invisible to most enterprise search and analytics systems because it cannot be queried with a LIKE clause without destroying its nuance.
What Vector Databases Enable
Consider two support tickets:
- The application crashes when I press the blue button after signing in on my mobile device.
- iOS app freezes following authentication on the main screen.
These tickets share almost no common vocabulary, but they describe the same problem. A vector database identifies them as near-duplicate vectors. No keyword search system can do this reliably.
This capability is foundational for:
- Corporate knowledge base and document searches.
- Customer support AI assistants grounded in real documentation.
- Compliance monitoring across unstructured communications
- How AI and machine learning are transforming ecommerce platforms through behavioral similarity search.
ACID Compliance: What Enterprise Architects Need to Know
Most purpose-built vector databases do not offer complete ACID compliance in the usual sense, though things are changing rapidly.
| Database | ACID Support | Vector Native | Notes |
| PostgreSQL + pgvector | Full | Extension | Best for hybrid transactional + retrieval needs |
| Pinecone | Partial | Yes | Prioritizes throughput over strict consistency |
| Weaviate | Partial | Yes | Offers tunable consistency settings |
| Qdrant | Partial | Yes | Strong at metadata filtering, async writes |
| Zilliz Cloud (Milvus) | Improving | Yes | Moving toward stronger consistency guarantees |
| SingleStore | Full | Hybrid | Combines RDBMS and vector search in one engine |
The preferred architecture for cases requiring transactional integrity and semantic retrieval would be hybrid: an RDBMS would serve as the system of record, and a synced vector index would act as the secondary lookup layer.
Metadata Filtering: Where Precision Meets Semantic Search
One underappreciated feature of high-powered vector databases is metadata filtering. This is a process of combining vector-based searches with filters applied to scalar properties.
Take, for example, a legal document retrieval application. You can customize the search for documents to be:
- Semantically similar to a query about “breach of contract in software licensing.”
- AND date newer than January 2023
- AND tagged with jurisdiction = “US Federal”
A pure vector query cannot enforce conditions 2 and 3. A pure scalar query cannot handle condition 1. Together, that’s what makes enterprise vector databases so precise.
Modern systems like Weaviate and Qdrant provide native support for pre- and post-filtering metadata, making them well-suited for the fine-grained retrieval required by custom AI consulting for enterprise data architecture.
Self-Hosted vs. Managed Vector Databases
| Factor | Managed (Pinecone, Zilliz Cloud) | Self-Hosted (Milvus, Qdrant, Chroma) |
| Operational Overhead | Zero, fully managed | Requires DevOps capability |
| Query Latency | Sub-10ms via global infrastructure | Depends on hardware configuration |
| Data Residency | Provider-controlled (check compliance) | Full sovereignty, data stays on-prem |
| Cost Model | Per-query plus index size pricing | Infrastructure cost only at high volume |
| GPU Indexing | Limited options | Supported (Milvus, Qdrant) |
| Best For | Fast time-to-value, early-stage | Regulated industries, high-volume, data sovereignty |
For most enterprises beginning their vector database journey, a managed solution significantly reduces time-to-value. Organizations with mature ML platform teams and strict data governance requirements often find self-hosted deployments to be more cost-effective over a 2- to 3-year horizon.
When Should a Business Choose a Hybrid Database Approach?
In real-world business applications, there are two layers required that complement each other:
- A relational database is used for transactions, users, inventory, orders, and workflows that require strict ACID compliance.
- A vector database (or a vector store extension) for semantic searches, recommendations, similarity searches, and injection of LLM context.
Recommended Hybrid Architecture
| Layer | Technology | Responsibility | Example Tool |
| 1 | Operational (RDBMS) | Structured data, transactions, schema enforcement | PostgreSQL, SQL Server |
| 2 | Vector Retrieval | Semantic search, embedding index, RAG context | Pinecone, pgvector, Qerdrant |
| 3 | Reasoning (LLM) | Response generation, summarization, synthesis | Azure OpenAI, GPT-4, Claude |
Teams building AI-driven enterprise apps using Microsoft Azure commonly combine this pattern with
- Azure Cosmos DB for operational data
- Azure AI Search for vector retrieval
- and Azure OpenAI for the reasoning tier.
At CMARIX, we have implemented this hybrid architecture across fintech, healthcare, and SaaS clients, and the pattern consistently outperforms both “all-in on vector” and “retrofitting RDBMS for AI” approaches in terms of reliability, cost, and performance, resulting in better AI software development solutions.
Embedding Models: Choosing the Right Foundation
No discussion of vector databases is complete without addressing how embeddings are created, since the quality of your vectors determines the quality of your retrieval.
| Model | Hosted/Open | Best For | Notes |
| OpenAI text-embedding-3-large | Hosted | General NLP retrieval | High quality, per-token pricing |
| Sentence-Transformers (HF) | Open Source | Data privacy, multilingual | Self-hostable, strong multilingual support |
| Cohere Embed v3 | Hosted | Retrieval tasks | Optimized for document vs query asymmetry |
| Domain-Specific (fine-tuned) | Both | Legal, medical, finance | Highest recall in specialized domains |
Choosing the wrong embedding model for your domain is one of the most common early mistakes in RAG deployments. The Hugging Face documentation on embeddings and the
Pinecone Learning Center guide on vector embeddings is a strong starting point for understanding the foundational concepts before making architectural decisions.
NLP vs. LLM: Choosing the Right AI Approach
| Dimension | Classical NLP | LLM-Based |
| Labeled Data Needed | Small-to-medium datasets | Zero-shot or few-shot capable |
| Interpretability | High, auditable outputs | Requires evaluation frameworks |
| Inference Latency | Sub-10ms for small models | 500ms to 3s or more via API |
| Reasoning Complexity | Structured, known schemas | Open-ended, multi-step tasks |
| Cost at Scale | Low, fixed infrastructure | Per-token pricing can escalate |
In many cases, the solution to this question involves both a classic NLP layer for efficient filtering and entity extraction, followed by an LLM stage for synthesis. To learn more about how this approach is made, refer to our article on choosing between NLP and LLM architectures.
Building Production-Grade Vector Search: Key Architectural Decisions
1. Index Type Selection
- HNSW: Better recall and lower latency for real-time applications.
- IVF: More memory-efficient at a very large scale. Many teams use HNSW with periodic IVF snapshots.
2. Chunking Strategy
- Fixed-length chunking: Simple and straightforward, but often inadequate for retrieval performance.
- Semantic chunking: By breaking chunks at paragraph or section boundaries, we can greatly enhance the retrieval performance of RAG models.
3. Two-Stage Retrieval with Re-Ranking
A two-stage approach, vector search for top-100 candidates, followed by a cross-encoder re-ranker for the final top-5, yields meaningfully better results than pure ANN search alone, at the cost of additional latency. Worth implementing for high-stakes retrieval applications such as legal, compliance, or medical.
4. Embedding Refresh Pipelines
Your vector index will have to change as your underlying data changes. Building resilient embedding, refreshing pipelines, and setting stale thresholds will not be easy.
5. GPU-Accelerated Indexing
In case you require less than 50ms response time for billion-sized indexes, then the use of GPU-indexed vector search engines like Milvus and Qdrant will give you enough compute capacity.
Why CMARIX for Your Vector Database and AI Infrastructure
CMARIX is a full-stack AI engineering partner, not just a consulting firm. We design, build, and operate production AI systems, including the vector database infrastructure that makes them reliable and scalable.
Here is what differentiates CMARIX when it comes to vector database and AI infrastructure projects:
| Capability | What It Means for You |
| Production RAG Experience | We have deployed RAG pipelines across fintech, healthcare, and SaaS clients, with retrieval latency benchmarks under 200ms in production |
| Hybrid Architecture Design | We architect systems that combine existing RDBMS with vector retrieval, avoiding costly rip-and-replace migrations |
| Model Selection Expertise | We evaluate and recommend the right embedding model for each domain, not just default options |
| Legacy System Integration | We specialize in connecting AI capabilities to existing .NET, Java, and Azure-based enterprise systems without disrupting live operations |
| Dedicated AI Teams | We offer flexible engagement models, from advisory and architecture reviews to full dedicated AI development squads |
| End-to-End Delivery | From vector index design to LLM orchestration to front-end AI interfaces, CMARIX delivers the full stack |
CMARIX works with enterprise teams at every stage of the AI infrastructure journey — from evaluating whether pgvector is sufficient for your current scale, to designing a multi-cloud vector architecture for billion-parameter retrieval workloads.

Making the Right Infrastructure Decision for Your AI Application
This is not an either-or proposition, but rather an architectural one. Some of the best enterprise AI projects have used these tools as complementary components of an integrated data platform rather than competing solutions.
In building AI systems for search engines, recommendation engines, natural language processing, and conversational interfaces, the question is no longer whether to include vectors; it is how to do so efficiently.
Whether you are evaluating managed services, planning a self-hosted deployment, or designing a RAG pipeline from scratch, the architectural decisions you make in the next 6 to 12 months will significantly shape your AI capabilities for years.
FAQs When Comparing Vector and Traditional Databases
Can traditional databases like PostgreSQL handle vector data?
PostgreSQL does indeed manage vectors efficiently using the pgvector extension. Embedding intelligence with Vector Search and RAG Models can be stored in a designated vector format, and specialized indexes such as HNSW (Hierarchical Navigable Small World) can be used to perform fast similarity queries in a relational setting.
Why are vector databases preferred for LLMs and Generative AI?
Vector databases are optimized for high-dimensional similarity searches at scale, which is essential for providing LLMs with long-term memory (RAG). They handle the mathematical complexity of comparing millions of embeddings in milliseconds, a task that would overwhelm the indexing structures of most standard databases.
What is the main difference between scalar search and vector search?
Scalar search relies on exact matches or range-based logic (e.g., searching for a specific ID or price), whereas vector search identifies data based on semantic similarity. Vector search understands the “meaning” of data by calculating the mathematical distance between points in a multi-dimensional space.
Do vector databases support ACID compliance?
Many have, especially those based on an existing engine architecture or enterprise-specific (e.g., Pinecone, Milvus, or PostgreSQL with vector support). Although at first many “vector-only” companies favored performance over ACID, ACID is now the preferred standard to maintain data consistency when using AI.
When should a business choose a hybrid database approach?
A hybrid approach is best when a business needs to combine structured metadata filtering with semantic retrieval. This is critical for applications like e-commerce, where a user wants to find “shoes that look like these” (vector) but only those that are “in stock and under $100” (scalar).




