Quick Overview: Choosing between self-hosted AI and OpenAI APIs is one of the biggest infrastructure decisions enterprises face in 2026. This blog breaks down cost, compliance, performance, customization, and vendor risk, so you can make the call with confidence. Neither option wins universally. The correct answer depends on your team, workload, and data.
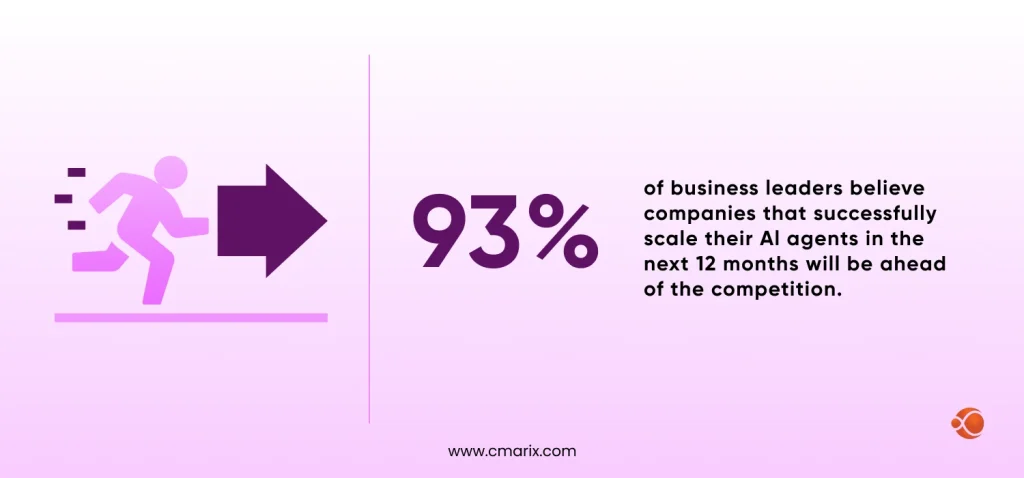
Here’s a number to think about: 93% of business leaders believe that businesses that successfully scale their AI agents over the next 12 months will be ahead of the competition. And this isn’t a soft prediction. It is a hard prediction. This is a clear signal that the infrastructure decisions you make around AI right now are going to be reflected in your bottom line and your position relative to your competition in the next 12 months.
Yet, most enterprise teams are still caught in the same debate: do we develop and control our own AI infrastructure, or do we call OpenAI’s API and ship faster?
The answer is not necessarily obvious. Both ways have trade-offs, and both ways work. And, ultimately, the wrong choice for your particular workloads, team skills, and requirements can mean millions in unnecessary spend, regulatory liability, or a product that simply cannot scale.
Who This Guide Is For
- Technical leaders evaluating AI infrastructure decisions
- CTOs are considering the trade-offs between the cost, control, and compliance of AI infrastructure
- Enterprise architects designing scalable infrastructure for AI solutions
- Decision-makers who want to understand the differences between self-hosting AI and OpenAI for enterprises, without the fluff.
Let’s begin with the basics
Self-Hosted AI vs OpenAI APIs: How Each Approach Works
What is Self-Hosted AI?
Self-hosted AI means your company runs the model on infrastructure you control. That could be on-premise servers in your own data center, or a private cloud environment like a dedicated AWS VPC or Azure private instance.
This means you’re downloading a model, often from Hugging Face’s model repository or a similar source, and running inference on your own GPUs. You control the runtime, the scale, and the security perimeter. Tools like vLLM handle the GPU orchestration and the inference throughputs, and the existence of open-weight models like the ones provided by Meta’s Llama 3.x framework has made this route viable.
If you need hands-on help with infrastructure setup, working with certified AWS developers for scalable AI hosting can significantly reduce setup time and risk.
Common deployment models include:
- Private cloud (AWS, GCP, Azure) with isolated compute
- On-premise GPU clusters (full control, highest capital cost)
- Hybrid setups where sensitive workloads stay local and general tasks hit the cloud
What are OpenAI APIs?
OpenAI’s API platform lets you call state-of-the-art models GPT-4o, o3, and the latest in the GPT family, over HTTPS, paying per token. You don’t manage any infrastructure. The standard API platform documentation covers the full feature set, which includes function calling, assistants, vision, embeddings, and more.
For most teams starting out, this is the fastest path from idea to working product. The operational overhead is near zero; you send a request, you get a response, you pay for what you use.
Self-Hosted AI vs OpenAI APIs: Key Differences at a Glance
| Factor | Self-Hosted AI | OpenAI APIs |
| Infrastructure Ownership | You own and manage it | OpenAI manages everything |
| Cost Structure | CapEx-heavy upfront | OpEx, pay-per-token |
| Scalability | Manual GPU provisioning | Auto-scales on demand |
| Customization | Full fine-tuning control | Limited to prompt engineering + fine-tune API |
| Maintenance | Your team’s responsibility | Handled by OpenAI |
| Data Residency | Stays within your perimeter | Processed on OpenAI’s infrastructure |
| Time to Deploy | Weeks to months | Hours to days |
Make the Right AI Investment Decision
AI infrastructure choices directly impact long-term costs. Get a tailored breakdown based on your workload and scale.
Cost Comparison: Which Option is More Economical?
Cost is where this decision gets complicated fast.
With OpenAI APIs, you’re looking at pure OpEx — no servers to buy, no GPU leases to negotiate. At low-to-moderate volumes, this is genuinely cost-efficient. But the token costs compound.
An enterprise running millions of API calls per day will start seeing GPU costs in the $2,000–$15,000/month range on the API side, sometimes more, depending on model tier and context length. Getting a clear picture of measuring enterprise AI investment returns before committing to either path helps you build a defensible business case internally.
Self-hosted AI flips the model. You’re spending upfront on GPU hardware (or reserved cloud GPU instances), usually ranging from $10,000 to $500,000+, depending on scale. Add ongoing costs for cooling, electricity, DevOps time, and model updates. But once that infrastructure is paid for, marginal inference costs drop significantly.
A useful rule of thumb by business size:
- Early-stage or SMB: OpenAI APIs almost always win on economics. The overhead of managing your own infrastructure isn’t worth it unless you have a hard compliance requirement.
- Mid-market (50–500M in revenue): It depends on the workload volume. If you have a predictable volume of inference, then self-hosting becomes a financially viable option, especially for high-volume inference on a narrow set of tasks. Token tax mitigation, caching, and small language models for simple tasks become a real cost lever here.
- Enterprise (500M+): At the enterprise level, self-hosting usually wins on cost. The infrastructure investment quickly reduces when you’re running thousands of concurrent inference requests. That said, maintaining the team expertise to run it adds to the true cost of ownership.
Hidden costs worth flagging: inference latency optimization engineering, model versioning, security audits, and the ongoing work of keeping up with model updates; none of these show up in a simple CapEx (Capital Expenditure) vs OpEx (Operating Expenditure) comparison.
Data Privacy, Security, and Compliance Considerations
This is the section that often settles the debate for regulated industries.
- OpenAI’s enterprise privacy commitments include SOC 2 Type II compliance, zero data retention (ZDR) policies for API calls, and the option for data processing agreements under GDPR. That’s solid for most use cases. For healthcare (HIPAA), defense contractors, financial services (PCI-DSS, SOX), or any organization with very stringent data geopatriation policies, “your data doesn’t leave our servers” is not the same as “your data doesn’t leave your country, your network, or your control.” With ZDR policies, you’re still sending your sensitive data across the internet to a third party’s infrastructure.
- Self-hosted AI eliminates that entirely. Your data stays in your perimeter. You control who can access it, how it’s logged, and where it physically sits. Gartner’s 2026 strategic technology forecast specifically identifies “AI Security Platforms” and geopatriation as top enterprise priorities this year.
For agentic workflow security, self-hosted environments provide you with capabilities that simply aren’t possible when calling a third-party API:
- Constrain model behavior without depending on prompt-level guardrails
- Audit every tool call at the infrastructure level
- Implement zero-trust architectures across your entire AI stack
- Maintain full observability of every model interaction and data access event
This matters enormously for AI agents in enterprise defense and similar high-stakes deployments.
Performance and Scalability: What to Expect
Inference latency optimization is one area where the comparison isn’t as clear-cut as it seems. OpenAI’s infrastructure is optimized at a massive scale. For most applications, API response times are fast, typically 500ms to 2 seconds for standard completions. Their global infrastructure handles load spikes automatically.
Self-hosted AI provides you with more control but also more responsibility. With proper GPU orchestration using tools like vLLM and NVIDIA’s TensorRT, you can achieve lower latency for high-throughput, batch-cluster workloads. But you’re also responsible for avoiding bottlenecks. An under-provisioned GPU cluster or a misconfigured inference server will directly hurt your users.
Key things to consider:
- Latency-sensitive apps (real-time chat apps, voice apps): Edge wins unless you’ve spent time optimizing inference.
- Batch processing apps (document analysis, nightly processing jobs): Self-hosted wins because you’re not charged by token, and you can optimize throughput.
- Uptime guarantees: OpenAI provides uptime guarantees. Self-hosting is only as available as your own infrastructure and team.
Customization and Control
If your use case requires a model that behaves in particular ways, follows your brand voice, operates under strict behavioral constraints, or understands proprietary terminology, then customization matters.
- OpenAI does offer fine-tuning through their API, but it’s limited compared to what you can do with full model access. You can’t change the base weights arbitrarily, and you’re working within their infrastructure constraints.
- Self-hosted AI gives you full access to model weights. You can run data preparation for LLM fine-tuning on your proprietary datasets, iterate on training runs, and deploy a model that’s genuinely specialized for your domain. This is where self-hosting really shines for industries like legal, medical, or financial services, where general-purpose models often fall short. Machine learning development solutions focused on fine-tuning can help you get there without building the entire pipeline from scratch.
- Integration flexibility is another dimension. When you’re building on top of an enterprise AI integration framework you control, you can wire the model directly into internal systems without routing through external APIs, cleaner architecture, lower latency, simpler security model.
Time-to-Market and Deployment Speed
OpenAI APIs win here, and it’s not close.
You can have a working prototype in an afternoon. There’s no infrastructure to provision, no model to download, no GPU drivers to configure. For fast prototyping and MVPs, this speed advantage is real and significant.
Self-hosted AI is a multi-week or multi-month project, depending on your starting point. You need to provision infrastructure, evaluate and download models, set up inference runtimes, configure security, and then test thoroughly. If your team doesn’t have deep ML engineering experience, add significant time for the learning curve.
That said, strategic AI consulting can compress that timeline substantially, bringing in teams who’ve done this before, which eliminates most of the trial-and-error. When evaluating specialized AI development services, look specifically for teams with prior self-hosted deployment experience in your industry.
Enterprise Use Cases: When to Choose What
When Self-Hosted AI Makes Sense
- You’re in a regulated industry (finance, healthcare, defense, legal) with strict data residency or compliance requirements
- Your workloads are large-scale and predictable; you know roughly how much inference you’ll run each month
- You need full model control for domain-specific fine-tuning
- Long-term cost optimization is a priority, and you have the engineering team to support it
- Agentic workflow security requirements demand full observability of every model interaction
When OpenAI APIs Are the Better Choice
- You’re building an MVP or proof-of-concept, and speed to market matters most
- Your development team lacks the ML infrastructure expertise to run models reliably in production
- Workloads are variable or unpredictable; you don’t want to over-provision GPU capacity
- You need access to the latest model capabilities without managing upgrades yourself
- Budget is constrained upfront, and OpEx is easier to justify than CapEx
Not sure in which category you fall into? It helps to start by comparing AI agents and off-the-shelf solutions against your actual requirements before defaulting to either path.
Build AI Systems That Work in Production
From API-first MVPs to fully self-hosted deployments, CMARIX helps you design and scale AI systems tailored to your needs.
Hybrid AI Strategy: Combining Self-Hosted and OpenAI API Models
Most mature enterprises don’t pick one or the other; they build a hybrid architecture. And in 2026, this is becoming the dominant pattern. A standard hybrid architecture looks like this: customer-facing features with variable load, OpenAI APIs for handling general-purpose tasks, and rapid experimentation.
Self-hosted models generally include Meta Llama models running in a private VPC for handling sensitive data processing, domain-specific tasks, and high-volume batch workloads where cost control is important.
This approach gives you the best of both: speed and flexibility from the API layer, cost efficiency, and data control from the self-hosted layer. The routing logic between the two is where the real engineering challenge sits; you need smart orchestration to decide which model handles which request, and you need LLM evaluation frameworks to ensure quality doesn’t degrade at the seams.
Vendor Lock-In vs Ownership: Strategic Trade-offs
| Risk Factor | OpenAI APIs | Self-Hosted AI |
| Pricing changes | OpenAI controls pricing — can shift anytime | You control infrastructure costs |
| API deprecations | Models get deprecated, forcing migrations | You version and manage models yourself |
| Model behavior shifts | Updates can alter outputs without warning | Full control over model versions |
| Vendor roadmap dependency | Tied to OpenAI’s product decisions | Swap open-weight models freely |
| Team capability dependency | No ML expertise needed to maintain | Relies heavily on in-house ML engineers |
| Model quality staying current | Always on the latest OpenAI models | Fine-tuned models can fall behind SOTA |
| Portability | Stack is tied to OpenAI’s infrastructure | Infrastructure is yours to move or rebuild |
Some enterprises take portability further, moving models to the edge devices entirely, where vendor dependency drops to near zero but a new set of challenges opens up. Secure AI development for on-device applications is a discipline of its own, and one worth planning for before models leave your central infrastructure.

What Factors Should You Consider When Choosing the Right AI Deployment Approach?
Before choosing, work through this checklist:
Data and Compliance
- Does your data include PII, PHI, or other regulated content?
- Do you have geopatriation or data residency requirements?
- What are your audit and logging requirements for AI interactions?
Technical Readiness
- Do you have ML infrastructure engineers in-house? If not, it may be time to hire AI developers for enterprise solutions before committing to a self-hosted path.
- What’s your current GPU capacity or cloud GPU budget?
- Have you evaluated your enterprise AI agents implementation framework?
Business Priorities
- Speed to market vs long-term cost optimization, which matters more right now?
- Are workloads predictable or variable?
- What’s your tolerance for vendor dependency?
Questions to Ask Vendors
- What are your data retention and processing policies?
- How do you handle model updates? Can we pin to a specific version?
- What SLAs do you offer for uptime and latency?
For companies considering custom enterprise software development that incorporates artificial intelligence, these questions should be answered before starting the work.

Future Trends in Enterprise AI Deployment (2026 and Beyond)
Three shifts are worth watching closely.
Rise of Private AI Infrastructure
Gartner’s forecasts and enterprise buying patterns both point in the same direction: more organizations are investing in dedicated AI infrastructure. The cost of GPU compute continues to fall, and open-weight model quality continues to rise, making the economics of self-hosting more attractive each year.
Growth of API Ecosystems
At the same time, API-based AI is getting more capable and more specialized. Vertical-specific models, OpenAI whisper API integration services, and multi-modal capabilities mean the API path keeps expanding what it can do without requiring you to manage anything.
Edge AI
The next frontier is running smaller, effective models at the edge, on devices, in branch offices, or in environments with limited connectivity. SLMs (Small Language Models), purpose-built for specific tasks, will increasingly complement both self-hosted and API-based deployments. This is where AI model fine-tuning services focused on compression and quantization are becoming strategically important.
Why Enterprises Trust CMARIX for AI Infrastructure Decisions
CMARIX has worked with enterprises across regulated industries to architect and deploy production AI systems. Whether you’re building from scratch or optimizing an existing setup, the team brings hands-on experience with both API-first architectures, from infrastructure setup to enterprise AI integration.
If you’re at the point of making this infrastructure decision, it’s worth a conversation before you commit; the wrong architecture choice is significantly easier to avoid than to unwind. Reach out through custom API development services to get started.
If you’re at the point of making this infrastructure decision, it’s worth a conversation before you commit; the wrong architecture choice is significantly easier to avoid than to unwind.
Conclusion: Making the Right AI Investment Decision
The self-hosted AI vs. OpenAI debate for enterprises doesn’t have a universal answer, and anyone who tells you it does is oversimplifying. What it does have is a clear decision framework. Begin with your compliance and data requirements; those are often non-negotiable.
Then, of course, you must think about the technical depth of your team, your schedule, and your workloads. For most enterprises, the reality in 2026 is likely to be a mix of both, with self-hosting for control and cost-effectiveness at scale, and APIs for flexibility and speed.
What matters most is that you make this decision deliberately, with full visibility into the trade-offs, before your architecture is already locked in.
If you want help thinking through the specifics for your organization, custom API development services and enterprise AI strategy are exactly where we can help.
Abbreviations Used in the Blog
| Abbreviation | Word |
| LLM | Large Language Model |
| VPC | Virtual Private Cloud |
| SOC 2 | System and Organization Controls 2 |
| GDPR | General Data Protection Regulation |
| HIPAA | Health Insurance Portability and Accountability Act |
| PCI-DSS | Payment Card Industry Data Security Standard |
| SOX | Sarbanes-Oxley Act |
| ZDR | Zero Data Retention |
| OpEx | Operating Expenditure |
| CapEx | Capital Expenditure |
| PII | Personally Identifiable Information |
| PHI | Protected Health Information |
| SLA | Service Level Agreement |
| SLM | Small Language Model |
Frequently Asked Questions: Self-Hosted AI vs OpenAI APIs for Enterprises
Is Self-Hosted AI more cost-effective than OpenAI APIs in 2026?
That also depends on the scale. For small to moderate volumes, it is likely that the cost of using OpenAI APIs is less when you consider infrastructure as well as engineering costs. However, in high volumes where there is a predictable workload, there is an upfront investment cost. The crossover point varies by organization, but most enterprises start seeing self-hosted economics make sense somewhere in the range of tens of millions of API calls per month.
How does Data Sovereignty differ between OpenAI and Self-Hosted AI?
With OpenAI APIs, your data is transmitted to and processed on OpenAI’s infrastructure; even with ZDR policies, it leaves your network perimeter. Self-hosted AI keeps all data processing within your own infrastructure, which is why it’s the default choice for industries with strict data residency or geopatriation requirements. This is a binary distinction, not a spectrum.
What is the main performance trade-off of hosting AI locally?
The main trade-off is that the performance ceiling depends entirely on your infrastructure investment. OpenAI’s globally distributed infrastructure handles load spikes automatically. Self-hosted systems require you to provision for peak load under-provision, and you get latency spikes; over-provision, and you’re wasting GPU spend. Inference latency optimization requires dedicated engineering attention that doesn’t exist in the API model.
Can enterprises integrate Agentic AI into self-hosted environments?
Yes, and for many enterprises, self-hosted environments are actually better suited for agentic workflows precisely because you have full control over tool call auditing, security boundaries, and model behavior constraints. The challenge is that agentic systems require more sophisticated orchestration infrastructure; plan for it before you commit to an architecture.
What technical stack is required for an enterprise to self-host an LLM?
At minimum: GPU infrastructure, an inference runtime like vLLM or TensorRT-LLM for GPU orchestration, a model serving layer, a security/access control layer, or monitoring and observability tooling. For fine-tuned models, you also need data pipelines, training infrastructure, and model versioning systems.