In a world where digital information doubles in size almost every two years, traditional search engines and interfaces might not be the best tools at your disposal to access all such information. This frustration is driving a monumental shift in how we interact with information systems through embedding intelligence and semantic search AI.
The answer most technocrats are leaning towards is vector search technology and Retrieval-Augmented Generation (RAG) models that improve AI experiences. These intelligent search systems are fundamentally changing how users discover information, interact with applications, and receive personalized experiences across industries.
According to Addsearch, the average user abandons 68% of their searches due to poor search experience. Embedding-based search techniques are designed to solve these pain points.
AI Driven User Experience and Rise of Future Intelligent Interaction with Embedding Intelligence
Why Traditional Search Falls Short in 2025
Keyword-based search has been the golden standard for SERP rankings, and the biggest tool for SEO experts to secure top ranks on popular search engines. This traditional keyword-based search relies mainly on exact matches and boolean operations.
For instance:
If a user wants to search for a budget smartphone with a good camera as their priority, they would likely search “budget smartphone with a good camera”. The results probably will not show up articles or websites that would have described the product as “affordable mobile phones with excellent photography”.
Both the search queries target the exact same product, but are still missed when not worded exactly. This limitation is known as the semantic gap between user intent and system understanding which leads to frustration. The problem grows especially acute for specialized domains such as legal research, healthcare and technical documentation.
Moreover, keyword search often lacks contextual understanding or user intent. A search for “apple” could refer to the fruit, the big tech company, or even a records management software. Until the search is backed by semantic understanding with embedded intelligence, systems will just try making the best guess, with inconsistent accuracy.
The Rise of Semantic Search AI in Modern UX
Semantic search AI is a fundamental shift that prioritizes meaning-based interactions. Modern users are accustomed to their technology understanding what they mean, not just what they say. Even a popular data gathering and visualization platform like Statista has its own dedicated generative AI solution – Research AI, that uses semantic search embeddings, large language models and Retrieval Augmented Generation to address user queries.
This rise of AI-driven semantic search mimics human interaction patterns and prioritizes concepts, relationships, and context – not just keywords. Benefits of RAG models in AI helps developers in making relevant connections and enhancing user experience with semantic AI search capabilities.
What is Vector Search in AI and Why is it Important for User Experience?
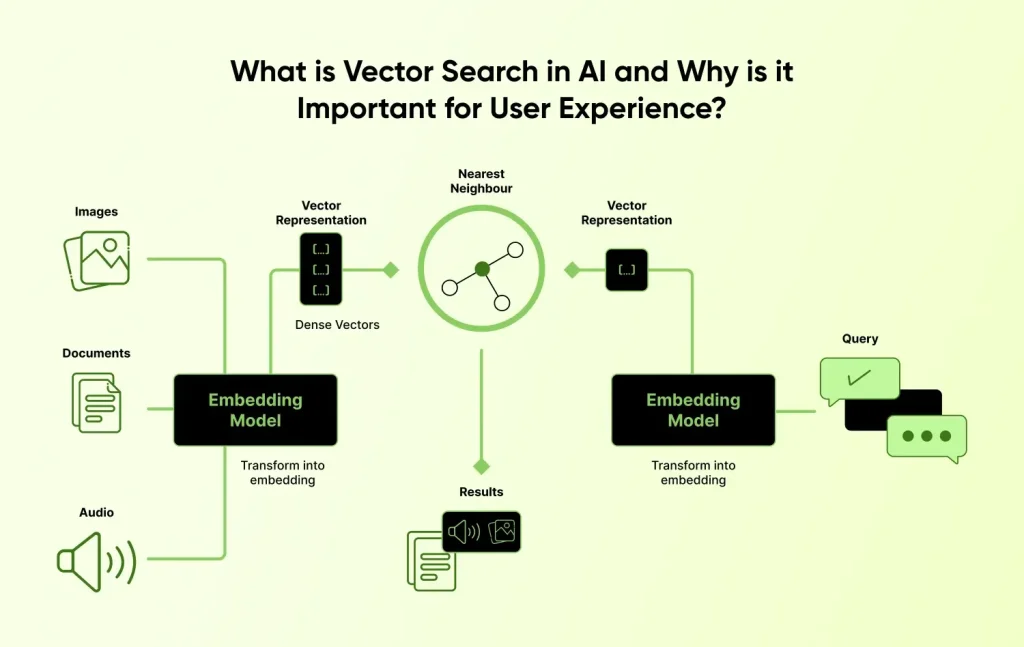
Vector embeddings or Vector search translates words, phrases, and concepts into a mathematical model. It converts language into coordinates on a meaning or context map. Words that have similar meanings are clustered together in the vector database for AI applications.
For instance, “automobile”, “car”, “vehicle”, “sedan”, will all be mapped to nearby points in vector space. Hence, when a user searches for “affordable automobiles” or “affordable vehicles”, the intelligent embedded search engine understands the user’s intent is to find budget cars or inexpensive vehicles, without limiting its search to the exact phrase of traditional keywords.
These embeddings are a result of deep neural networks trained on massive datasets. Real-world models such as BERT and Ada from OpenAI convert language into hundreds and thousands of numeric dimensions. Each dimension holds subtle aspects of meaning which would be missed by traditional systems entirely, giving generative AI solutions the edge over them.
Vector Search vs Keyword Search Tabular Comparison
| Feature | Traditional Search (Keyword-Based) | Vector Search (Semantic/Embedding-Based) |
| Search Method | Relies on exact keyword matching | Uses vector embeddings to capture semantic meaning |
| Technology Base | Boolean search, inverted indexes | Machine learning, neural networks, vector databases |
| Query Understanding | Literal interpretation of words | Understands context, intent, and meaning |
| Result Relevance | High precision, low recall; exact matches | High recall; retrieves conceptually similar results |
| Handling Synonyms | Poor; requires manual synonym mapping | Strong; captures synonyms and related concepts automatically |
| Performance on Misspellings | Limited; needs fuzzy matching | Better tolerance via embedding similarity |
| Scalability | Scales well with mature indexing tools | Requires more compute power and optimization for large datasets |
| Use Cases | Exact document retrieval, rule-based systems | AI chatbots, semantic search, recommendation engines |
| Data Format Support | Structured text (e.g., product names, titles) | Unstructured data (text, audio, image via embeddings) |
| Integration Complexity | Easier to implement with traditional tools (e.g., Elasticsearch) | Needs embedding generation, vector DBs (e.g., FAISS, Pinecone) |
Understanding Retrieval-Augmented Generation (RAG) Models in AI
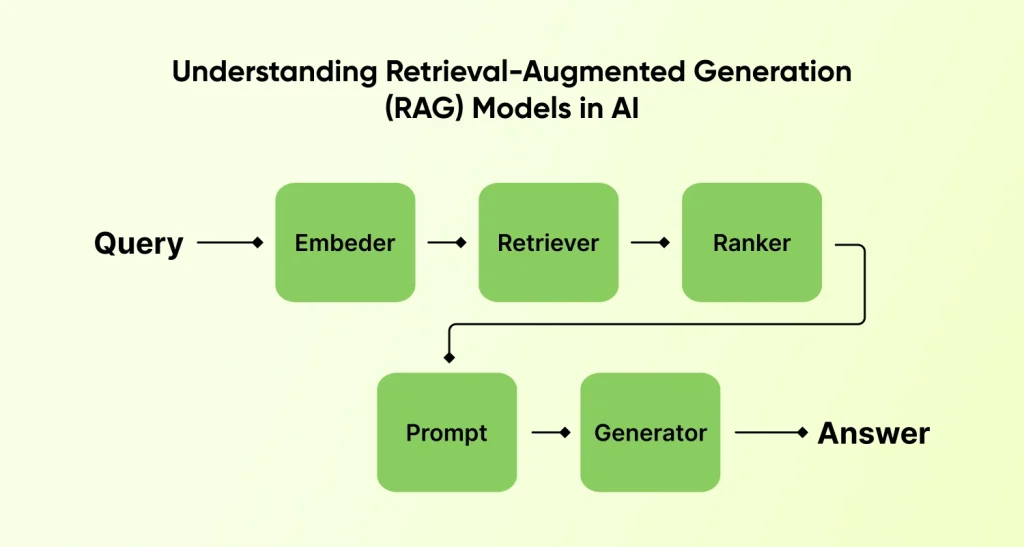
RAG architecture combines two strong AI components: a retriever and a generator. What does this mean? Well, the retriever uses vector search for finding relevant information from a knowledge base. The generator then creates natural language responses using the retrieved information, which creates the foundation of intelligent search systems.
This RAG architecture provides a strategic advantage over standard large language models (LLMs) which is limited access to specific or current information. If a user asks about “recent developments in protein folding research”, a standard LLM might generate some response, but chances of it being outdated or incorrect would be significantly higher. RAG models however would retrieve the latest papers on the subject matter before generating a response.
This retrieval step is often known as “knowledge filter” which uses vector algorithms. The generation step then uses this information and creates a contextual response, directly addressing the user queries, which is a key benefit of RAG models in AI applications. Hire AI developers from a reliable next-gen development company with experience in implementing custom vector-based RAG models as per industry standards and requirements.
How RAG Improves LLM Accuracy and Context?
Standard LLMs have the biggest problem of hallucination, which is confidently generating incorrect information. RAG models are able to reduce hallucinations by 73% as per a study published in the Journal of Artificial Intelligence Research, marking them essential for AI PoC development services that focus on accuracy.
Since RAG builds responses around retrieved documents, it is able to provide verifiable information with proper resources. This creates transparency and trustworthiness important for business applications. Users are able to trace assertions back to their origins, rather than having to blindly believe AI-generated information as the whole truth.
Use Cases of RAG in Product Design and Customer Support
| Use Case | Description |
| Customer Support Automation | Instantly retrieves company data to generate accurate, personalized responses. |
| Inquiry Scalability | Handles up to 40% more support queries without increasing staff. |
| Internal Knowledge Systems | Converts documents into interactive systems for accurate internal answers. |
| Employee Self-Service | Delivers context-aware answers about internal tools and processes. |
| Technical Documentation Help | Assists developers with API usage and complex feature implementation. |
| Developer Productivity | Speeds up troubleshooting using precise, doc-based AI guidance. |
How to Combine Vector Search with RAG for Next-Gen AI Applications?
Vector search is the foundation of any effective RAG system. The system receives a user-query and converts it into a vector embedding. It then searches the entire database for AI applications containing semantic traces of similarity from credible knowledge sources.
Organizations usually have rich embeddings of their documentation, knowledge bases, and other authoritative content converted to vector databases. These databases are optimized for similarity searches across endless documents within milliseconds, making it a crucial capability for AI software development services.
The retrieval process kicks in to identify the most relevant documents collected on semantic similarity, improving the relevance of fetched information that will be used by the generator, for providing more accurate, contextual and user-intent specific responses.

Top Use Cases of RAG in Product Design and Enhancing AI User Experiences
| Use Case | Primary Benefit | Industry Examples |
| Question Answering Systems | Precise information retrieval | Enterprise support, education platforms |
| Content Recommendation Engines | Personalized discovery | Media streaming, e-commerce |
| Semantic Search in Documents | Natural language understanding | Legal, research, knowledge management |
| Multi-modal AI Systems | Cross-format understanding | Creative tools, accessibility solutions |
| Enterprise Knowledge Base Chatbots | Context-aware corporate information | Internal tools, customer service |
Question Answering Systems
Question-answering systems are one of the most primary use cases of RAG implementations. It enables users to get precise answers extracted from relevant documents.
It combines vector search with language model reasoning to locate and synthesize information from credible extensive knowledge bases. They provide contextually correct responses rather than document links, significantly improving information accessibility and user satisfaction across enterprise support platforms and educational tools.
Content Recommendation Engines
Vector search RAG models are also popularly used by content recommendation engines to transform discovery experiences by studying the semantic essence of content rather than relying on metadata or user behaviour patterns.
These systems are able to encode articles, products, videos and other content formats into vector representations. They compare similarity between user preference and content embeddings, to enable RAG-powered recommendations that achieve greater relevance and discovery depth.
Semantic Search in Large Document Repositories
Semantic search powered by RAG can be beneficial for enterprises that have large repositories with no efficient and accurate way of finding relevant documents at the right time. Implementing custom RAG models can help better understand user query intent than performing literal keyword matching.
Organizations like research institutions, legal firms and corporates see significant improvement in document retrieval times, as they are able to raise queries using natural language, to receive relevant results, even if the exact terminology does not match.
Intelligent Chatbots with Access to Company Knowledge Bases
When you power intelligent chatbots with RAG capabilities, it transforms your organizational knowledge accessibility by connecting conversational interfaces with overall corporate information.
These systems are able to retrieve and reason over internal documents, policies, product specifications, and support histories. Doing so, they are able to provide contextually relevant, accurate responses unlike previous-generation chatbots that could only answer in confinement of predefined answers.
Multi-Modal AI Systems
Multi-modal RAG systems represent the cutting edge of retrieval-augmented generation by incorporating diverse data types—text, images, audio, and video—into unified AI experiences. These solutions can retrieve relevant information across formats, enabling applications like visual product search, audio-enriched medical analysis, and multi-format creative tools.
By understanding relationships between different media types, multi-modal RAG creates more intuitive interfaces where users can interact naturally using their preferred information format, breaking down traditional barriers between content types and creating more accessible AI experiences.
Best Tools and Frameworks for Building Vector Search and RAG Systems
Vector Databases
Vector databases are crucial components in modern AI applications, enabling efficient storage and retrieval of high-dimensional embeddings.
1. FAISS
Facebook AI Similarity Search (FAISS) is an open-source library by Facebook AI Research that delivers exceptional performance for vector similarity search. It offers highly optimized algorithms with GPU acceleration but requires substantial implementation expertise compared to managed solutions. FAISS is ideal for organizations with strong engineering teams that need precise control over indexing mechanisms and can handle billions of vectors with proper configuration.
2. Pinecone
Pinecone provides a fully-managed vector database designed specifically for machine learning applications with minimal configuration required. It offers optimized production deployment capabilities with automatic scaling but provides less flexibility than self-hosted solutions with usage-based pricing. Pinecone excels for teams looking to minimize operational overhead while handling millions of vectors efficiently through built-in sharding.
3. Weaviate
Weaviate focuses on hybrid search capabilities that combine vector similarity with traditional keyword searching. It features a GraphQL API with a schema-based approach that effectively merges semantic and lexical search but requires more complex setup than fully-managed options. Weaviate is particularly suitable for applications with complex data relationships that benefit from both semantic understanding and keyword precision.
4. RedisVector
RedisVector leverages Redis’s in-memory processing architecture to deliver exceptional query speed for vector operations. It offers seamless integration with existing Redis infrastructure and sub-millisecond latency but faces memory-bound scaling that can increase costs for very large indices. RedisVector shines in use cases where query speed is critical and dataset size remains manageable.
RAG Implementation Frameworks
These frameworks provide the essential building blocks for implementing retrieval-augmented generation systems with minimal boilerplate code.
1. LangChain
LangChain offers a comprehensive ecosystem for building retrieval-augmented applications with a modular architecture and extensive integration options. It features an active community but has a rapidly evolving API that can lead to deprecation issues in production systems. LangChain excels for rapid experimentation with key components including document loaders, text splitters, vector store integrations, and sophisticated agent frameworks.
2. Haystack
Haystack specializes in document retrieval pipelines with robust PDF parsing and comprehensive document preprocessing capabilities. It supports multiple retrieval approaches but focuses more on retrieval mechanisms than full RAG workflows. Haystack is ideal for document-heavy applications requiring sophisticated pipeline architecture with reader-retriever patterns and built-in evaluation frameworks.
3. LlamaIndex
LlamaIndex (formerly GPT Index) provides simple APIs for data ingestion, query engines, and complex routing patterns for large language model applications. While less mature than other frameworks, it’s rapidly developing and particularly valuable for projects requiring flexible connections to diverse data sources. Its key features include specialized data connectors, index structures, and agent tools optimized for LLM interaction.
Large Language Models for RAG
The choice of LLM significantly impacts generation quality, embedding effectiveness, and operational costs in RAG systems.
1. OpenAI Models
OpenAI delivers high-quality models with exceptional response quality and continuous improvement through a robust API. While offering premium performance, these models come with premium pricing and limited customization options compared to open-source alternatives. OpenAI’s GPT-4 and GPT-3.5 Turbo excel for generation tasks while their text-embedding models provide efficient vector representations, though per-token pricing becomes significant at scale.
2. Cohere
Cohere specializes in efficient embeddings and generation with transparent pricing models and strong multilingual support. While offering high-quality embeddings specifically optimized for RAG applications, Cohere operates within a smaller ecosystem than OpenAI. Their Command series powers generation tasks while the Embed series creates vector representations, with more flexible enterprise pricing options available for large-scale deployments.
3. Hugging Face Models
Hugging Face enables deployment of open-source models with complete control and no vendor lock-in. Supported by a vibrant community, these models require infrastructure expertise to manage and optimize effectively. Hugging Face offers a wide range of models including Llama 2, Mistral AI, and BERT variants, with infrastructure costs replacing per-token fees—often more economical at scale.
4. Anthropic Claude
Anthropic Claude models feature strong reasoning capabilities with exceptionally long context windows that enhance document processing capabilities. They deliver nuanced understanding with high accuracy but offer fewer embedding-specific options than specialized alternatives. The Claude model series comes with varying capabilities and context lengths, providing competitive pricing alongside high-quality outputs for comprehensive RAG applications.
Vector Search Optimization Techniques
Advanced techniques can significantly enhance retrieval quality beyond basic vector similarity searching.
1. Hybrid Search
Hybrid Search combines vector similarity with keyword-based retrieval to capture both semantic meaning and lexical precision. This approach requires careful tuning of combination weights to balance these signals effectively. Implementation typically involves BM25 or similar algorithms alongside vector search, delivering improved recall especially for queries with specific terminology or proper nouns.
2. Re-ranking
Re-ranking applies a secondary scoring pass on initial retrieval results to improve precision through more sophisticated models. While this approach adds latency to the retrieval process, it dramatically improves result quality by applying computationally intensive methods to a smaller candidate set. Modern implementations utilize cross-encoders or specialized smaller LLMs that examine query-document pairs holistically.
3. Dense Passage Retrieval (DPR)
DPR utilizes trained bi-encoders specifically optimized for retrieval tasks with better alignment between queries and documents than generic embeddings. This approach typically requires domain-specific training data to achieve optimal results for specialized applications. DPR implementations use separate encoders for queries and documents, trained with contrastive learning techniques that maximize relevance signals.
Final Words
Vector search and RAG models represent a transformative evolution in information access. By understanding intent rather than just keywords, these technologies enhance user satisfaction, maximize knowledge utilization, and improve operational efficiency. Organizations embracing semantic intelligence are relying on Artificial Intelligence consulting services that are setting new standards for digital experiences. As these systems mature, they’ll become expected rather than exceptional, creating information ecosystems that truly understand users’ needs—even when they aren’t sure how to ask.
FAQs on Vector Search and RAG Models
What Is Vector Search, and How Does It Work?
Vector search transforms words and concepts into mathematical representations (vectors) in multi-dimensional space where similar meanings cluster together. It converts user queries into these same vector spaces and finds matches based on semantic similarity rather than exact keywords, enabling systems to understand intent beyond literal words.
How Does Vector Search Improve User Experience?
Vector search improves user experience by understanding meaning behind queries rather than requiring exact keyword matches. Users can phrase questions naturally and still receive relevant results, reducing frustration from “no results found” messages and enabling discovery of information they didn’t know to specifically request.
Is RAG the Future of Knowledge Management?
RAG represents a significant evolution in knowledge management by combining retrieval systems with generative AI. Unlike traditional knowledge bases that simply store information, RAG creates dynamic, contextual responses while reducing hallucinations.
How Can Businesses Integrate Rag Models Into Their Digital Platforms?
Businesses can integrate RAG by converting high-value knowledge repositories into vector databases and implementing search infrastructure using tools like FAISS or Pinecone. Starting with targeted use cases such as customer support, companies should continuously optimize relevance and response quality through testing and refinement.
Can Vector Search and Rag Models Be Used in Chatbots and Virtual Assistants?
Vector search and RAG models transform chatbots from rigid, script-based tools into intelligent systems that connect conversational interfaces with organizational knowledge. These assistants provide contextually relevant answers drawn from documentation and specifications, generating accurate responses that cite sources while dramatically improving user experience.